AIモデル
1. 量子化技術の戦略的定義と推論効率のメカニズム
大規模言語モデル(LLM)のプロダクション導入において、量子化は単なる「圧縮技術」ではなく、VRAMという極めて高価かつ限定的なリソースの「動的最適化戦略」と定義される。モデルの重みをFP16/BF16から低ビット精度(8/6/4/2-bit)へ変換することは、8Bクラスのモデルであっても16GBから5GB以下への劇的なメモリ削減をもたらすが、真の戦略的価値はその「余白(Headroom)」の創出にある。
推論ボトルネック:「メモリーウォール」とKV Cacheの競合
LLMの推論速度(tok/s)を支配するのは、演算能力(FLOPS)ではなく、VRAMからデータを転送する「帯域幅」の制約、いわゆる「メモリーウォール」問題である。しかし、シニア・アーキテクトが注視すべきは、モデル重みの転送量削減だけでなく、**KV Cache(Key-Value Cache)**とのリソース競合である。
最新のモデル(Llama 3やGemma 3等)は、GQA(Grouped Query Attention)を採用してKV Cacheの肥大化を抑制しているが、依然として長文コンテキストの推論ではKV CacheがVRAMを大量に消費する。量子化によって重みデータの転送量を削減しつつ、VRAMの空き容量を確保することは、スループットの向上だけでなく、ビジネス要件である「長大な文脈(Context Window)」への対応能力を直接的に拡張することを意味する。
精度とトレードオフの定量的評価
Source Contextに基づく、8Bモデルを基準とした精度(パープレキシティ)とモデルサイズの相関関係は以下の通りである。
| 精度設定 | メモリ占有率 (8B) | 品質維持率 (推定) | 戦略的位置づけ |
| BF16 (基準) | 16.4 GB | 100% | 研究・微調整用ベースライン |
| 8-bit (Q8_0) | 8.5 GB | 99.5% | 品質最優先時のデファクト |
| 6-bit (Q6_K) | 6.7 GB | 98.0% | プロダクション環境の黄金比 |
| 4-bit (Q4_K_M) | 4.7 GB | 95.0% | コンシューマ機・エッジ展開用 |
| 2-bit (IQ2_M) | 2.5 GB | 85.0% | 研究・プロトタイプ・極限環境 |
--------------------------------------------------------------------------------
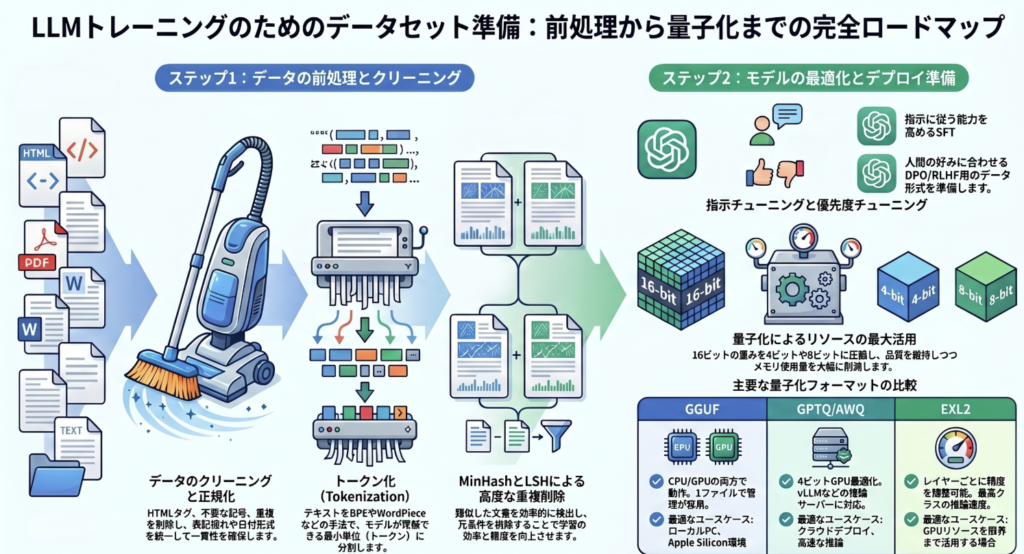
2. 主要量子化形式の技術特性と実務的比較分析
デプロイ環境の多様化に伴い、形式選定は「インフラの柔軟性」と「純粋な実行速度」のどちらを優先するかで決定される。
各形式の技術的優位性と設計思想
- GGUF(llama.cpp系):ヘテロジニアス環境の「保険」 混合精度整数量子化により、CPU/GPU間でのレイヤーオフロードを柔軟に制御可能。シングルファイル形式によるポータビリティの高さから、不特定多数のハードウェアが混在する環境における「標準保険」として機能する。
- GPTQおよびAWQ:vLLMエコシステムの基盤
- GPTQ: キャリブレーションデータを用い、4-bitにおいて高い整合性を維持する。vLLM等の推論サーバーでLoRAアダプターを併用する場合、現状で最も安定した選択肢となる。
- AWQ: アクティベーション(活性化)の重要度を分析し、重要な重みを保護する。GPTQに対し、特定のタスクで精度面での優位性を示す。
- EXL2:GPU専用の最高速エンジン レイヤーごとにビット数を可変(bpw)させる「職人的」な割り当てを行う。GPU推論に特化しており、GGUF比で3〜4倍高速という圧倒的な実行パフォーマンスを誇る。
- NVFP4:Blackwell世代のハードウェア・ネイティブ RTX 5090やB100/B200に搭載された「専用FP4テンソルコア」を直接駆動する。従来の整数コア(Integer compute)を使用するGGUFとは一線を画すスループットを実現するが、Qwen3-8BでのベンチマークではMMLU-Pro(難解な論理推論)で79.4%、**AIME24(数学)で81.8%**まで精度が低下するリスクを孕んでいる。
技術特性比較テーブル
| 形式 | 主要フレームワーク | ハードウェア依存 | 推論速度(感度) | 実務的インパクト |
| GGUF | Ollama, llama.cpp | 低 (汎用) | 1.0x (基準) | 安定性と汎用性重視の環境に。 |
| EXL2 | ExLlama v2 | 高 (NVIDIA) | 3.0〜4.0x | GPUリソース専有時の最高速解。 |
| GPTQ | vLLM, AutoGPTQ | 中 (NVIDIA) | 2.0x | vLLMでのLoRA運用における標準。 |
| NVFP4 | vLLM | 極めて高 (Blackwell) | 2.5x〜 | Blackwell専用。高負荷環境に。 |
--------------------------------------------------------------------------------
3. インフラ環境に基づいたハードウェア依存度の評価
インフラ設計者は、物理的制約から逆算して量子化形式を決定しなければならない。
VRAM制約下でのバス帯域マネジメント
VRAM容量を超えるモデルを動作させる際、システムRAMへのオフロードは回避不能な選択肢となるが、PCI Expressバス経由のデータアクセスはVRAM内部帯域に比べ劇的に遅い。1レイヤーでもRAMに溢れた瞬間、スループットは致命的に低下する。したがって、可能な限り「VRAMに全て収まる量子化ビット数」を選択することが、システム応答速度を保証する最低条件となる。
ハードウェア世代別の最適化
- Blackwell世代(RTX 5090 / B100等): NVFP4をネイティブサポートする唯一の環境だが、前述の「精度劣化」が許容できない論理タスクでは、あえてVRAM帯域を活かせるQ6_K GGUFやEXL2 (5.0bpw以上)を選択することが、サービス品質の安定化に繋がる。
- Legacy環境(Pascal世代 P40等) / CPU環境: これらの環境はFP16演算能力が著しく低いため、FP4/FP8等の最新フォーマットは適合しない。整数量子化(Integer Compute)を効率的に回せるGGUFが、実質的な唯一の選択肢となる。
--------------------------------------------------------------------------------
4. 多言語(特に日本語)環境における品質維持の設計指針
日本語環境における量子化選定では、英語とは異なる「劣化の非対称性」を理解する必要がある。
低リソース言語(日本語)の「攻撃的劣化」
LLMのトレーニングデータの40-60%は英語が占めており、日本語トークンのモデルキャパシティは相対的に小さい。過度な量子化(4-bit以下)を強行すると、強固な学習背景を持つ英語能力よりも先に、日本語の論理構造や微細なニュアンスが損なわれる。特に、数値計算や価格算出を伴うビジネスロジックにおいて、4-bit環境では「日本語での論理破綻(Logic Breakage)」が生じるリスクが極めて高い。
戦略的スイートスポット:Q6_K(6-bit)
日本語の品質と推論速度のバランスを追求する場合、**Q6_K(6-bit)**がプロダクション環境のゴールドスタンダードである。FP16比較で品質を約98%維持しつつ、メモリを半分以下に抑えることができる。4-bit(Q4_K_M)へ移行してさらに2GBのVRAMを節約することに固執するよりも、この2GBを「日本語品質の保険料」として支払う方が、顧客向けサービスの信頼性向上において費用対効果が高い。
トークナイザーと埋め込み(Embedding)の脆弱性
英語のスペース区切りと異なり、日本語はMeCabやSudachiPy等の形態素解析器を前提とした複雑な構造を持つ。量子化によるベクトル空間の圧縮は、日本語特有の多義語や表記揺れの保持に悪影響を及ぼしやすいため、多言語展開では「Q6_K」を最低ラインと定義すべきである。
--------------------------------------------------------------------------------
5. 技術選定要領:意思決定マトリクスと推奨フロー
意思決定マトリクス
| 優先シナリオ | 推奨量子化形式 | 選定の論理 |
| ミッションクリティカル・高品質 | Q8_0 GGUF | 99.5%の品質維持。論理破綻の許されない用途。 |
| 商用プロダクション(標準) | Q6_K GGUF | 速度・精度・多言語対応の「黄金比」。 |
| マルチユーザー・商用スケーリング | GPTQ-Int4 / NVFP4 | vLLMでのスループット最大化。LoRA運用ならGPTQ。 |
| リソース制限・エッジ展開 | Q4_K_M GGUF | 4.7GBまで圧縮。動作継続性を最優先。 |
実務的なステップバイステップ・ガイド
- デフォルトの基準選定: まずは Q6_K GGUF から開始する。これが、品質低下を最小限に抑えつつ、スループットを最大化できる現代のインフラにおける「基準点」である。
- ダウンサイジングの条件: VRAM不足によりロード不可、あるいはKV Cache用のHeadroomが致命的に不足する場合にのみ、Q4_K_M への移行を検討する。その際は、日本語での「論理的な思考ステップ」に誤りがないか厳密に検証すること。
- 特定の要件への切り替え:
- LoRA併用: vLLM環境での GPTQ-Int4 へ移行。
- 超高速GPU推論: VRAMに余裕がある単一ユーザー環境であれば EXL2 を選定。
- Blackwell環境: 数値演算が不要な大量リクエスト処理に限り NVFP4 を検証。
最終チェックリスト
- [ ] 日本語論理性検証: 日本語の複雑な推論(特に価格計算や条件分岐)で誤答していないか。
- [ ] KV Cache Headroom: 量子化後の空きVRAMが、目標とするコンテキスト長を処理できるか。
- [ ] ハードウェア特性: ターゲットGPU(Blackwell/Pascal/CPU)に最適化された演算コア(FP/Integer)を利用しているか。
以上が、インフラ環境とビジネス要件を高度に両立させるための技術選定フレームワークである。