Llama 4の3つのバリアント(Scout、Maverick、Behemoth)は、それぞれコンテキストウィンドウのサイズ、パラメータ数、および想定される用途において明確な違いがあります。
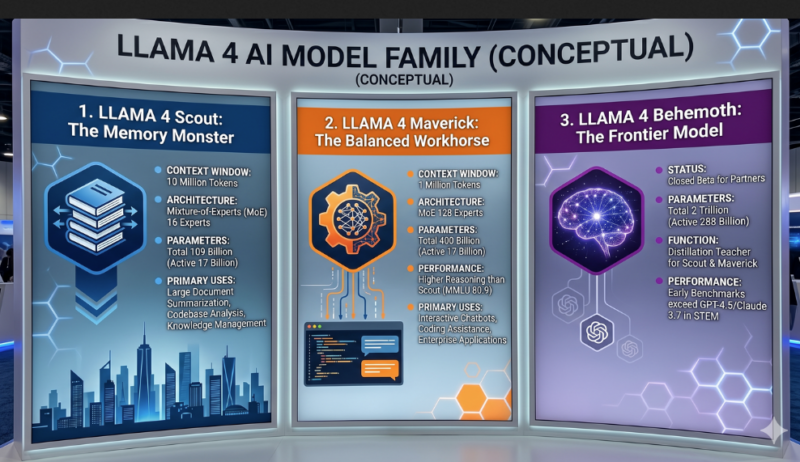
1. Llama 4 Scout(超巨大なコンテキスト特化)
- 特徴: 「The Memory Monster(記憶の怪物)」と呼ばれ、1000万トークンという驚異的なコンテキストウィンドウを持っています。
- アーキテクチャ: 16のエキスパートを持つMixture-of-Experts(MoE)アーキテクチャを採用しており、総パラメータ数1090億のうち、一度に170億パラメータをアクティブにします。
- 主な用途: マニュアル全体や大規模なコードアーカイブ、ビデオのトランスクリプトなどを一度に処理できるため、長い文書の要約、複数ファイルのコード分析、すべてを「記憶」する必要がある知識管理システムなどに最適です。
2. Llama 4 Maverick(推論とコストのバランス型)
- 特徴: 「The Balanced Workhorse(バランスの取れた主力機)」と呼ばれ、100万トークンのコンテキストウィンドウを持っています。
- アーキテクチャ: 128のエキスパートを持つMoEアーキテクチャで、総パラメータ数4000億のうち、Scoutと同じく170億パラメータをアクティブにします。エキスパート数が多いため、より専門的な推論が可能です。
- 性能と用途: MMLUスコアで80.9(Scoutは75.2)を記録するなど、推論タスク(特にコーディングや技術分析)においてScoutを上回る性能を発揮します。対話の文脈を失わないインタラクティブなチャットボットや、精度とスピードが求められるコーディングアシスタント、コストパフォーマンスを重視するエンタープライズ用途に向いています。
3. Llama 4 Behemoth(最高性能のフロンティアモデル)
- 特徴: 総パラメータ数2兆(アクティブ2880億)を誇る、Metaの最先端モデルです。
- 位置づけ: 現在は一部のパートナーや研究機関向けのクローズドベータ版として提供されており、一般の開発者が直接利用するのではなく、ScoutやMaverickに知識を「蒸留」するための教師モデルとして機能しています。
- 性能: 初期のベンチマークでは、STEM(科学・技術・工学・数学)分野においてGPT-4.5やClaude Sonnet 3.7を上回るパフォーマンスが示唆されています。
まとめると、広大なコンテキストが必要な場合はScout、高い推論能力とコスト効率のバランスを求める一般的なアプリケーション開発にはMaverickが適しており、Behemothはこれらを裏で支える巨大な教師モデルという位置づけになります。
Llama 4導入計画指針:2026年におけるエンタープライズAIの最適化
1. 戦略的背景:2026年におけるLlama 4ファミリーの意義
2026年初頭、エンタープライズAI市場は「クローズド独占からの脱却」という決定的な転換点を迎えています。MetaのLlama 4ファミリー(Scout、Maverick、Behemoth)の登場は、特定のクラウドベンダーへの依存(ベンダーロックイン)を回避し、AIインフラの主権を企業に取り戻す「セカンドソース・ムーブメント」の象徴となりました。
Llama 4はネイティブ・マルチモーダル設計と高度なエージェント機能を備え、テキスト・画像・動画・音声を単一のロジックで統合処理します。これにより、従来の「チャットUI」を超えた、自律的な業務遂行(エージェント)が可能になりました。市場には、Meta CTOのAndrew Bosworth氏が過去に「フォーカスの欠如」を懸念したようなリアルな市場評価も存在しますが、現在の2026年型モデルは、推論能力と効率性の両面で極めて高い完成度に達しています。
戦略的観点からは、AMD InstinctアクセラレータとROCmソフトウェアスタックの成熟が、NVIDIA/CUDAの独占を崩す選択肢を企業に与えたことも重要です。次章では、これらLlama 4ファミリーの各バリアントの技術的特性と、ビジネス価値を最大化する選定基準を詳述します。
--------------------------------------------------------------------------------
2. Llama 4モデル・アーキテクチャの詳細比較と選定基準
Llama 4は、総パラメータ数(Total Parameters)と稼働パラメータ数(Active Parameters)を分離したMixture-of-Experts (MoE) アーキテクチャを主軸としています。投資対効果(ROI)を最適化するには、タスクの複雑性と推論コストのバランスを精緻に見極める必要があります。
Llama 4 モデル・バリエーション比較(2026年1月時点)
| 項目 | Llama 4 Scout | Llama 4 Maverick | Llama 4 Behemoth |
| 総パラメータ数 | 1,090億 (109B) | 4,000億 (400B) | 2兆 (2T) |
| 稼働パラメータ数 | 170億 (17B) | 170億 (17B) | 2,880億 (288B) |
| MoE構成 | 16 エキスパート | 128 エキスパート | 高密度/MoE |
| 最大コンテキスト | 1,000万トークン | 100万トークン | 非公開 (教師モデル) |
| MMLU / GPQA | 75.2 / 58.7 | 80.9 / 67.1 | STEMドメインで世界最高 |
| 入力コスト (1M) | $0.08 | $0.15 | N/A (パートナー限定) |
| 出力コスト (1M) | $0.30 | $0.60 | N/A |
| 主要用途 | 巨大コンテキスト注入 | 高度な論理推論・構築 | 蒸留(教師)・最先端研究 |
「So What?」:アーキテクチャがもたらすビジネス価値
Scoutが情報の「網羅と抽出」に特化しているのに対し、Maverickは128個のエキスパートを搭載することで、論理構築における「専門知識の密度」を高めています。単にパラメータが多いだけでなく、特定ドメインに対する専門性の高さがMaverickのROIの源泉です。
次章では、Scoutが実現した1,000万トークンという巨大コンテキストが、いかに従来のRAGの概念を塗り替えるかを解説します。
--------------------------------------------------------------------------------
3. Llama 4 Scout:巨大コンテキスト(1,000万トークン)の戦略的活用
Llama 4 Scoutの最大の特徴である「1,000万トークン」のコンテキストウィンドウは、ナレッジマネジメントのパラダイムを「検索(Retrieval)」から「全量注入(Full Context Injection)」へとシフトさせました。
RAGから長期コンテキスト学習への移行
従来のRAG(検索拡張生成)では、大規模ドキュメントを「チャンク(断片)」に分割して検索するため、文脈の喪失やハルシネーションが課題でした。Scoutは、数万ファイルのコードベースや数年分の法務資料を「そのまま」入力可能です。これにより、検索漏れによる誤回答を根本から排除し、大規模なコード解析における依存関係の特定精度を飛躍的に向上させます。
具体的なビジネス実装シナリオ
- マルチファイル・コードベース解析: 数万のソースファイルにまたがる大規模リファクタリングの影響範囲を秒単位で特定。
- 長期文書の要約・検証: 過去10年分の会議録、仕様書、判例を一括投入し、長期的な整合性欠如を自動抽出。
- 法務ドキュメントの全件横断検証: 膨大な契約書群を一度に照合し、特定のリスク条項が全社的にどう分布しているかを完全に可視化。
Scoutは総パラメータ109Bのうち17Bのみを稼働させるMoE技術により、この巨大コンテキスト処理を入力$0.08/1Mトークンという、かつてないコスト効率で実現しています。続いて、より深い「推論」の質を求めるケースでのMaverickの役割を見ていきます。
--------------------------------------------------------------------------------
4. Llama 4 Maverick:高度な推論とコスト効率の最適均衡
Llama 4 Maverickは、2026年におけるエンタープライズの「主軸(ワークホース)」です。
専門知識の「密度」による高度な推論
MaverickはScoutと同じ17Bの稼働パラメータを持ちながら、総パラメータ数は400B、エキスパート数は128に達します。この「専門性の高さ」により、MMLU 80.9、GPQA 67.1という、複雑な論理構築能力を必要とするベンチマークでScoutを圧倒します。コーディング支援や高度な金融分析において、Maverickは最も信頼できる知性を提供します。
運用と微調整(Fine-tuning)のROI
100万トークンのコンテキストウィンドウは、通常の対話型タスクには必要十分であり、MoEの最適化によってレイテンシも実用範囲内に抑制されています。企業が独自のドメインデータで微調整を行う際、Maverickは「推論精度」「コスト」「処理速度」のバランスにおいて、現在最もROIが高い選択肢となります。
次章では、これら実務モデルの知性を背後で支える「教師」Behemothについて解説します。
--------------------------------------------------------------------------------
5. Behemothによる蒸留(Distillation)プロセスとエコシステムの恩恵
Llama 4 Behemothは2兆パラメータを誇る「教師モデル」であり、その知能はScoutやMaverickへの「蒸留」を通じてエコシステム全体に還元されています。
蒸留のパラダイムと30%のコスト削減
BehemothはSTEMドメインでGPT-4.5やClaude 3.7を凌駕する性能を持ち、その高度な論理回路が小型モデルの学習に利用されています。これにより、企業は巨大なBehemothを直接運用せずとも、その恩恵をMaverick等を通じて享受できます。
また、オープン・ウェイト・モデルであるLlama 4を、自社インフラ(AMD Helios等のラックスケール基盤)で運用することで、データの主権(データ・ソブリン)を確保しつつ、商用APIと比較して運用コストを約30%削減することが可能です。これは、ZT Systemsの統合によるラックスケール効率化の成果でもあります。
--------------------------------------------------------------------------------
6. インフラストラクチャの最適化:ハードウェア選定とスケーラビリティ
Llama 4の真価を引き出すには、2026年の最新ハードウェア基盤との親和性が鍵となります。
AMD Instinct MI400シリーズによる推論加速
オンプレミス展開において、AMD Instinct MI440Xは、19.6 TB/sの帯域を持つHBM4メモリにより、特にScoutのような巨大コンテキスト処理におけるデータ転送ボトルネックを解消します。ラックスケールでは、MI455Xを搭載したAMD Heliosプラットフォームが、yotta-scale(ヨタスケール)コンピューティングへの道筋を提示しています。
NVIDIA Earth-2との併用
特定ドメインでは、Llama 4のエージェント機能をNVIDIA Earth-2のような特化型モデルと連携させることが有効です。
- Atlas: 中長期気象予測モデル。
- StormScope: 分単位の局地的な降水・嵐のナウキャスティング。
- HealDA: 世界各地の観測データを統合する全球データ同化。 これらとLlama 4を組み合わせることで、エネルギー需要予測や災害リスク管理といった高度な意思決定支援が可能になります。
--------------------------------------------------------------------------------
7. 規制遵守とガバナンス:EU AI Act(2026年8月)への対応
2026年8月のEU AI Act施行は、全企業が避けて通れないハードルです。特にLlama 4を「高リスク(High Risk)」分野(雇用、金融スコアリング等)で利用する場合、厳格な義務が生じます。
2026年8月までの遵守チェックリスト
- [ ] EU法廷代理人の選任(Article 22): 非EU企業がEU市場でAIを展開する場合、EU内に認可代理人を置く義務。
- [ ] GPAI透明性要件の事後監査: 2025年8月に既に義務化されているGPAI要件(学習データの要約等)の遵守状況の再確認。
- [ ] 技術文書の完備: モデルの構築、データセット、バイアス評価の記録。
- [ ] 人間による監視(Human-in-the-loop): AIの意思決定に人間が介入できるメカニズムの構築。
- [ ] 適合性評価とCEマーキング: 認定機関による評価と適合マークの取得。
Llama 4のようなオープン・ウェイト・モデルは、クローズドなシステムよりも内部構造の透明性が高く、規制当局への説明責任を果たしやすいという戦略的メリットがあります。
--------------------------------------------------------------------------------
8. 実装ロードマップ:組織的導入に向けた3つのステップ
2026年初頭という現時点において、組織がとるべきアクションプランを提言します。
フェーズ1:アセスメント(第1四半期)
- アクション: ユースケースを分類し、情報の網羅(Scout)か推論の質(Maverick)かを決定。
- KPI: ROI予測の精度、モデル選定の妥当性。
フェーズ2:プロトタイピングと最適化(第2四半期)
- アクション: AMD MI440X等の自社インフラ上でのデプロイ。独自ドメインデータによるFine-tuning。
- KPI: 精度向上率、推論あたりの消費電力・コスト。
フェーズ3:スケールとコンプライアンス(第3四半期以降)
- アクション: EU AI Act(2026年8月期限)への準拠を完了させ、AMD Helios等のラックスケール基盤へ拡張。
- KPI: 業務時間削減率、法規制遵守の達成。
Llama 4の導入は、単なる技術のアップグレードではありません。2026年以降のデジタル主権を確立し、持続可能な競争優位性を構築するための、極めて戦略的な投資です。