2026年のデータエンジニアリングにおける主要な5つのトレンドは以下の通りです。
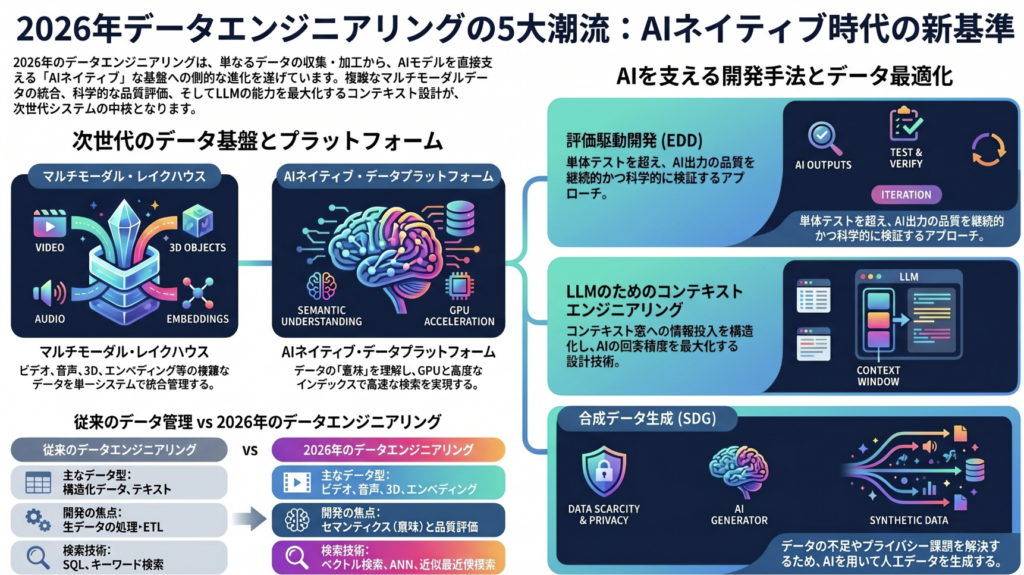
1. マルチモーダル・レイクハウス(Multimodal Lakehouses) 従来のデータレイクを進化させ、ビデオ、オーディオ、3Dモデル、エンベディングなどの複雑なデータ型を単一のシステムで統合的に保存・検索できるプラットフォームです。外部のインデックス作成を必要とせず、ストレージエンジンにベクトル検索が直接組み込まれているため、RAG(検索拡張生成)やAIモデルのトレーニングといったAIネイティブなワークフローに最適化されています。
2. 評価駆動開発(Evaluation-Driven Development: EDD) 評価テスト(evals)をAIやデータ開発の中核に据えるアプローチです。従来の単体テストを超え、AIや確率的システムのエンドツーエンドの出力品質を評価します。自動チェック、人間の判断、AI支援による採点を組み合わせることで、直感に頼るプロンプトエンジニアリングから脱却し、継続的かつ科学的な検証に基づいたシステムの改善を可能にします。
3. AIネイティブ・データプラットフォーム(AI-Native Data Platforms) 単なる生データの処理から、ビジネスコンテキストにおけるデータの意味(セマンティクス)の理解へと焦点を移したプラットフォームです。構造化データと非構造化データ(高次元のベクトルエンベディングを含む)の両方をシームレスに扱えるように設計されており、近似最近傍(ANN)などの高度なインデックス技術とGPUアクセラレーションを組み合わせて、高速でスケーラブルなクエリ実行を実現します。
4. LLMのためのコンテキストエンジニアリング(Context Engineering for LLMs) プロンプト(指示)の作成にとどまらず、LLM(大規模言語モデル)の限られたコンテキストウィンドウに「どのような情報を入れるか」「それをどう構造化するか」を設計する高度なアプローチです。システム命令、会話履歴、検索されたドキュメント、ユーザーデータ、ツールの出力など、モデルがアクセスできる情報の全体像を最適化し、AIの出力の関連性を最大化しつつ、遅延を最小限に抑えることを目的としています。
5. 合成データ生成(Synthetic Data Generation: SDG) 高品質な実際のデータが不足している場合や、プライバシーの観点で実際のデータが使いにくい場合に、ルール、アルゴリズム、または生成AIシステムを用いて人工的に作成されるデータのことです。現実世界のデータの統計的特性を模倣して生成され、希少なデータの補完、不均衡なデータセットの修正、機密情報の保護といった課題を解決しながら、モデルのトレーニングや評価(EDD)を支援します。