AIを「借りる」のではなく「所有する」という選択肢、非常にワクワクする領域ですね。2026年現在、オープンソース(OSS)のエコシステムは劇的に進化しており、数年前よりも遥かに簡単に、かつ高性能な環境を自前で構築できるようになっています。
自前でAI環境を用意するための主要な選択肢を、3つのステップに分けて整理しました。
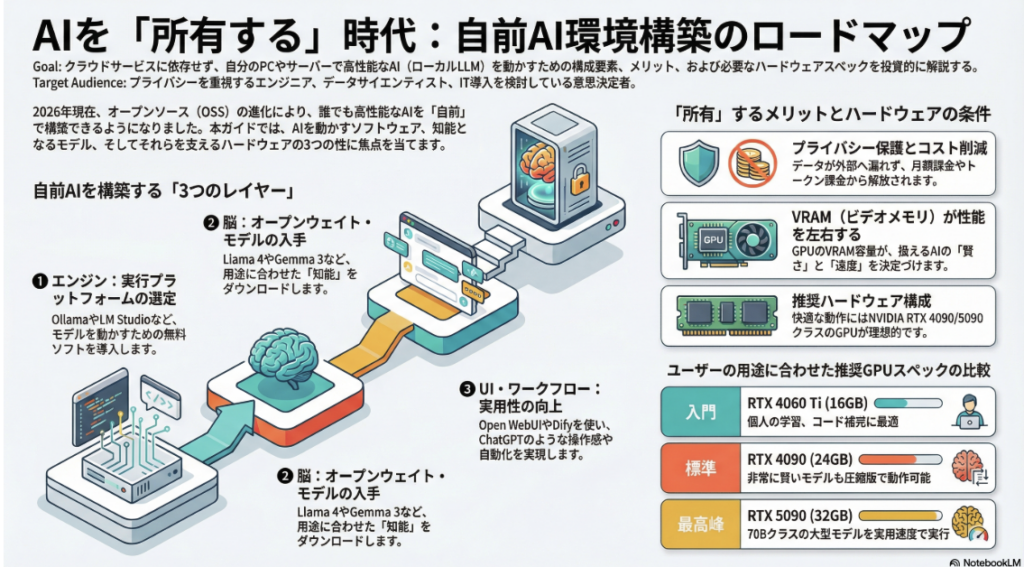
1. AIを動かす「エンジン」(実行プラットフォーム)
まずは、AIモデルを自分のPCやサーバーで動かすためのソフトウェアを選びます。これらはすべてオープンソース、または無料で利用可能です。
| ツール名 | 特徴 | 向いている人 |
| Ollama | 最も人気のあるツール。コマンド一つでモデルの導入から実行まで完結します。 | 手軽に始めたい初心者〜開発者 |
| LM Studio | 直感的なGUI(操作画面)で、モデルを探してダウンロードし、チャットができます。 | プログラミングに不慣れな人 |
| LocalAI | OpenAIのAPIと互換性があるため、既存のAIアプリの接続先を「自前AI」に差し替えられます。 | 自分でサービスを開発したい人 |
| vLLM | 大規模な運用に向いており、非常に高速な推論が可能です。 | 高スペックサーバーで運用したい人 |
2. AIの「脳」を選ぶ(オープンウェイト・モデル)
「モデル」はAIの知能そのものです。Hugging Faceというサイトから自由にダウンロードして使えます。
- Llama 4 / 3.1 (Meta製): デファクトスタンダード。非常に賢く、カスタマイズ用の資料も豊富です。
- gpt-oss (OpenAI製): OpenAIが公開したオープンウェイト版。推論能力が高く、指示に従う精度が非常に優秀です。
- Gemma 3 (Google製): 軽量で動作が軽く、家庭用PCでもサクサク動きます。
- Mistral / Qwen: 特定の言語(日本語など)やコーディングに強いモデルが多く、用途に合わせて選ばれます。
3. UIとワークフロー(使い勝手を良くする)
黒い画面(ターミナル)でチャットするだけでなく、ChatGPTのような画面や自動化ツールを組み合わせます。
- Open WebUI: ChatGPTそっくりのインターフェースを自前で立てられます。
- n8n: オープンソースの自動化ツール。自前AIとGoogleカレンダーやSlackを連携させ、「メールが来たら自前AIで要約して返信する」といった仕組みが作れます。
- Dify / LangFlow: 「AIエージェント」を作るためのツール。自社のドキュメントを読み込ませた専門AI(RAG)をGUIで構築できます。
自前環境にするメリットと課題
あえて自前で構築するからには、明確な理由が必要です。
- メリット:
- プライバシー: データが外部(OpenAIなど)に送信されないため、機密情報も扱えます。
- コスト: 一度ハードウェアを揃えれば、月額料金やトークン課金が発生しません。
- 検閲なし: モデルの制限を自分で調整でき、自由な回答を得られます。
- 課題:
- ハードウェア投資: 快適に動かすには、VRAM(ビデオメモリ)を多く積んだGPU(NVIDIA RTX 4090等)や、メモリを積んだMac(M2/M3 Max等)が推奨されます。
- 管理の手間: アップデートやセキュリティ対策を自分で行う必要があります。
まずはここから: もしお手元にMacやWindows PCがあるなら、まずは Ollama をインストールして、
ollama run llama3と打ってみてください。これだけで、あなたのPCの中に「誰にも覗かれないAI」が誕生します。
具体的にどのようなスペックのPCが必要か?
2026年現在のAI環境構築において、スペック選びで最も重要なのは**VRAM(ビデオメモリ)**の容量です。AIの「知能」はVRAMの中に展開されるため、この容量が扱えるモデルの大きさと賢さを決定します。
用途別に推奨されるスペックを「Windows/Linux(GPU重視)」と「Mac(メモリ共有型)」の2パターンで解説します。
1. Windows / Linux(NVIDIA GPU構成)
高速なレスポンスを求めるなら、NVIDIA製のGPU(GeForce RTXシリーズ)が王道です。
| ランク | 推奨GPU | VRAM | できることの目安 |
| 入門 | RTX 4060 Ti / 5060 Ti | 16GB | 8B〜14Bクラスのモデルが快適。個人の学習やコード補完に最適。 |
| 標準 | RTX 4090 | 24GB | 27Bクラスを高速実行。70Bクラス(賢いモデル)も圧縮版なら動作可能。 |
| 最高峰 | RTX 5090 | 32GB | 2025年に登場した新世代。30Bクラスを爆速で、70Bクラスも実用速度で動かせます。 |
- CPU: Intel Core i7 / Ryzen 7 以上(GPUが主役なので、そこまで最高級でなくてもOK)
- システムメモリ(RAM): 32GB〜64GB
- 電源: RTX 5090などを使う場合は 1000W〜1200W クラスの安定したものが必要です。

案A:NVIDIA構成(Windows/Linux)
「速度・画像生成・拡張性」を重視する場合
2026年現在、最新の RTX 5090 (VRAM 32GB) は単体で40万円〜50万円近くするため、予算50万円だと「GPU一点豪華主義」になります。一方、安定の RTX 4090 (24GB) を軸にすれば、他のパーツも高品質に揃えられます。
| パーツ | 構成案 (RTX 4090ベース) | 役割と理由 |
| GPU | GeForce RTX 4090 (24GB) | AIの心臓。24GBあれば大抵のモデルが爆速で動きます。 |
| CPU | Core i7-14700K / Ryzen 9 9900X | データの前処理やシステムの安定に必要。 |
| メモリ | 96GB (48GBx2) DDR5 | VRAMから溢れた際のバックアップとして大容量を確保。 |
| SSD | 2TB NVMe Gen4/5 | AIモデルは1つ数GB〜数十GBあるため、高速・大容量が必須。 |
| 電源 | 1000W - 1200W (80PLUS Gold以上) | 高消費電力なGPUを支える生命線。 |
メリット: 推論速度が非常に速い。画像生成(Stable Diffusion)も一瞬。
デメリット: 電気代と発熱が高い。非常に重いモデル(70Bクラス以上)は、性能を落とさないと入りきらない。
「50万円クラスのマシン」を想定し、そのポテンシャルを最大限に引き出すためのオープンソースAI環境の構築ステップを提案します。
1. 司令塔(推論サーバー)のセットアップ
まずはAIモデルをロードし、APIとして叩ける状態にします。
- Ollama (オールインワン型): 最も推奨されます。バックグラウンドで常駐し、モデルの切り替えが非常にスムーズです。
- Text Generation WebUI (多機能型): 「AIの実験室」と呼ばれます。サンプリングパラメータ(温度など)を細かく調整したり、複数のローダーを使い分けたい場合に最適です。
- vLLM (高速化特化): もしLinux環境でGPUを積んでいるなら、スループットが劇的に向上します。
2. 視覚化(ユーザーインターフェース)の導入
ターミナルではなく、ブラウザからChatGPTのように操作できる環境を作ります。
- Open WebUI: Dockerで1分で立ち上がります。RAG(ドキュメント読み込み)機能が標準搭載されており、PDFやウェブサイトを読み込ませて「自分の知識」を持ったAIを作れます。
- LibreChat: OpenAI, Anthropic, そして自分のローカルAIを一括管理できるUIです。
3. 「最強の脳」をダウンロードする
2026年現在、50万円クラスのマシン(VRAM 24GB〜 / RAM 64GB〜)で動かすべき鉄板モデルです。
- Llama-3-70B (量子化版): オープンソース界の王者。ビジネスメール、論理思考、翻訳まで、商用AIと遜色ない精度で動きます。
- DeepSeek-V3 / R1: プログラミングと数学において、GPT-4oを凌駕すると評されるモデル。
- Command R+: RAG(外部検索・参照)に特化したモデルで、長い文書を要約させるのに最適です。
4. 自動化・エージェント化(応用の極致)
単なるチャットで終わらせず、AIに「仕事」をさせます。
- Dify (一番おすすめ): ワークフロー作成ツールです。「メールを受信したら、ローカルAIが重要度を判断し、Slackに通知する」といった自動化をノーコードで組めます。
- Continue (VS Code拡張): エディタに自前AIを接続し、GitHub Copilotの代わりに使います。コードが外部に漏れないため、機密性の高い開発が可能です。
実装の優先順位
まずは以下の構成で「自分専用AI」を完成させるのが、最も満足度が高いはずです。
- Ollama をインストール
- Open WebUI を Docker で起動
- Llama-3-70B をダウンロードして対話してみる