AIの「コンテキストウィンドウ(Context Window)」とは、簡単に言うと「AIが一度に処理・記憶できる情報の範囲(キャパシティ)」のことです。
人間で例えるなら、「机の広さ」や「短期記憶の容量」に例えられます。机が広ければ広いほど、たくさんの資料を一度に広げて参照しながら作業ができますが、机からはみ出した資料の内容は、その瞬間の作業には反映されません。
1. コンテキストウィンドウの仕組み
AIは入力されたテキストを「トークン」という単位(単語や文字の一部)に分解して処理します。コンテキストウィンドウは、このトークンの最大保持量を指します。
- 入力と出力の両方が含まれる: ユーザーが送った質問だけでなく、AI自身の過去の回答やシステムへの指示(プロンプト)もこの枠を消費します。
- 「忘却」のメカニズム: 会話が長くなり、トークン数が上限を超えると、AIは古い情報から順番に忘れていきます。 先ほど話した内容をAIが急に無視し始めたら、それはコンテキストウィンドウの限界に達したサインです。
2. ウィンドウサイズが大きいメリット
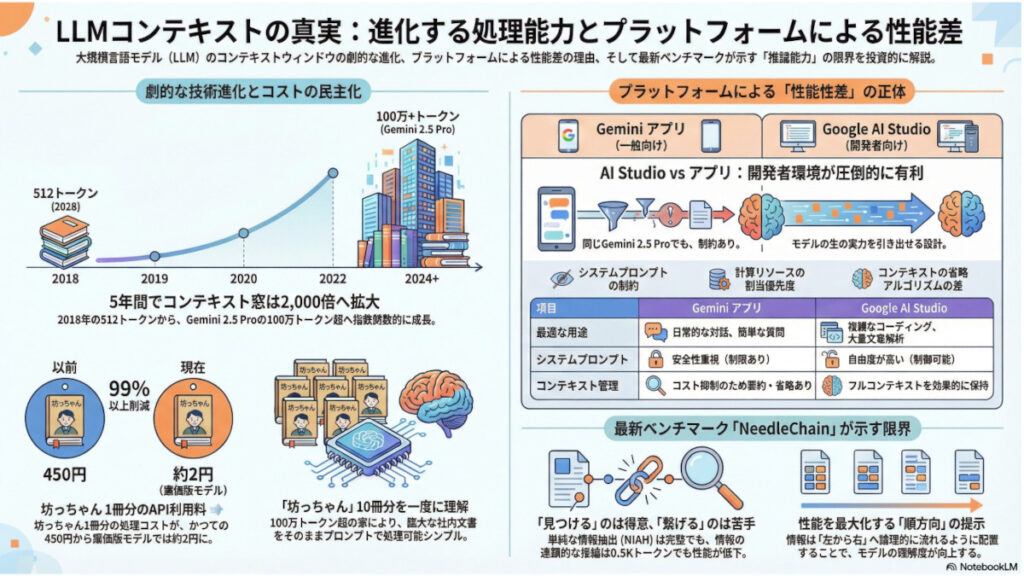
最近のAIモデル(Gemini 1.5 Proなど)は、このウィンドウが劇的に進化しており、数百万トークンを扱えるものもあります。
- 長大な資料の解析: 数百ページのPDFや、数万行のソースコードを丸ごと読み込ませて質問ができます。
- 一貫性の維持: 長い会話でも、最初の設定や文脈を忘れずに受け答えが可能です。
- 情報の横断検索: 大量のデータの中から、特定の細かい情報を探し出す(いわゆる「針を探す」タスク)精度が向上します。
3. 注意点と限界
コンテキストウィンドウが広いからといって、すべてが完璧になるわけではありません。
- 「中だるみ」現象: 情報量が多すぎると、情報の「最初」と「最後」はよく覚えているのに、「中間」にある情報を軽視してしまう傾向(Lost in the Middle)があります。
- コストと速度: 処理する情報量が増えるほど、計算リソースを消費するため、応答速度が遅くなったり、利用料金が高くなったりすることが一般的です。
- 精度の低下: 無関係な情報を大量に詰め込むと、AIが「何が重要か」を判断できず、回答の質が落ちる(ノイズに弱くなる)ことがあります。
4. 主要モデルの比較(2026年時点の目安)
現在の主要なAIは、用途に合わせて異なるサイズのウィンドウを提供しています。
| モデル名 | コンテキストウィンドウ(推定) | 特徴 |
| Gemini 3 Pro | 200万〜1,000万トークン | 圧倒的な広さ。動画や大量の書籍を一度に処理可能。 |
| GPT-5.2 | 12.8万〜51.2万トークン | 汎用性が高く、効率的な情報処理に特化。 |
| Claude 4 Opus | 20万〜50万トークン | 文脈の理解が深く、長文でも細部を忘れない。 |
APIとWEBで違いますよね
はい、おっしゃる通りです。API利用とWeb版(ChatGPTやClaudeのサイト)では、コンテキストウィンドウの扱いや制限において、決定的な違いがいくつかあります。
大きく分けて、「上限値」「制御の自由度」「料金体系」の3点に違いが現れます。
1. 「上限値(最大サイズ)」の違い
実は、同じモデル(例:GPT-4oやClaude 3.5 Sonnet)を使っていても、Web版の方がAPIよりもコンテキストウィンドウが小さく制限されていることがよくあります。
- Web版: サーバー負荷を抑えるため、モデル本来の性能よりも低い上限(例:数万トークン程度)で会話履歴が切り捨てられたり、要約されたりすることがあります。
- API: そのモデルが持つフルスペックのコンテキストウィンドウ(例:Claudeなら20万、Geminiなら200万以上)をそのまま利用できます。
2. 「記憶の管理」の自由度
ここが最も大きな違いです。
- Web版(AI任せ): 会話が長くなると、AI側が勝手に「古い話を忘れる」か「勝手に要約して記憶に留める」処理を行います。ユーザーは「何を覚えていて、何を忘れるか」を細かく制御できません。
- API(開発者が制御): APIは、リクエストを投げるたびに「過去のどの履歴を送信するか」を送信側(プログラム側)で1トークン単位で決定します。
- 特定の重要なルールだけをずっと残す。
- 直近10往復だけを送ってコストを抑える。
- 古い履歴は要約して送り、詳細は捨てる。 といったコントロールが可能です。
3. 「コスト」と「消費量」の関係
先日お話しした「週間利用制限」の話にも通じますが、コストの仕組みが異なります。
- Web版: 定額制(月額サブスク)が多いため、長いコンテキストを送り続けると運営側のコストが嵩みます。そのため、「利用制限(メッセージ回数制限)」が厳しくなりがちです。
- API: 「送ったトークン数 = 料金」の完全従量課金です。 コンテキストウィンドウをいっぱいに使って(例えば10万トークン分)1回質問すると、その分しっかり料金が請求されます。APIには「週間制限」のような回数縛りはありませんが、「長い文脈を送れば送るほど、1回の回答が高額になる」**という経済的な制約が生まれます。
まとめ
| 項目 | Web版 (ChatGPT, Claude等) | API (開発用) |
| ウィンドウサイズ | 制限されている場合が多い | モデルの最大値まで使用可能 |
| 記憶の制御 | 自動(制御不能) | 手動(自由自在) |
| 制限の性質 | 回数制限(5時間で○回など) | 予算制限(使った分だけ課金) |
| 主な用途 | 一般的な対話・作業 | アプリ組み込み・大量文書解析 |
「大量のPDFを一気に読み込ませて、細部まで正確に分析したい」というような場合は、Web版の制限に引っかかりやすいため、API(またはGoogle AI Studioのような開発者用ツール)を使う方が圧倒的に有利になります。
主要モデルのコンテキストウィンドウ比較(API vs Web)
| モデル名 | API/開発者向け(最大) | Web/一般向け(最大) | 特徴・補足 |
| Gemini 3 Pro | 1,000万トークン | プランによる | 圧倒的な容量。 書籍数千冊、動画・音声の長時間解析が可能。 |
| Llama 4 Scout | 1,000万トークン | - | オープンソースでありながらGeminiと同等の容量を持つ。 |
| Claude Sonnet 4/4.5 | 100万トークン (Beta) | 20万トークン | 「一貫性」重視。 長文でも情報の欠損が少ない。 |
| GPT-5 / 4.1 | 40万〜100万トークン | 3.2万〜12.8万トークン | バランス型。Web版はメモリ機能で補完。 |
- Geminiの圧倒的リード: Gemini 3 ProはAPI経由であれば1,000万トークンという桁違いの情報を一度に扱えます。これは動画や大量の資料を丸ごと読み込ませる際に決定的な差となります。
- Web版の制約: GPT-5クラスであっても、Web版では最大12.8万トークン程度に抑えられています。API版の最大値(100万)と比較すると、Web版は約8分の1から30分の1程度のサイズしか一度に処理できない計算になります。
- アプローチの違い: * Claude: Web版でも20万トークンと比較的大容量を維持しつつ、精度の高さを売りにしています。
- GPT: Web版のウィンドウ自体は小さめですが、過去の会話を記憶する「メモリ機能」などでその短所を補う戦略をとっています。
結論
もし「数万行のコードを読み込ませたい」「1時間の動画の内容をすべて踏まえて議論したい」といった高度なタスクを行うなら、Web版のチャット画面ではなく、API(またはGoogle AI Studioのような開発者ツール)を利用するのが2026年現在の正攻法と言えます。