
GPT-5.5の登場、非常にエキサイティングですね!2026年4月現在の最新情報に基づくと、今回のアップデートは単なる「賢さの向上」にとどまらず、コンピュータ上での「実務遂行能力(エージェント機能)」に特化した大きな進化を遂げています。
GPT-5.5の主な特徴と、移行に向けたポイントをまとめました。
🚀 GPT-5.5 の主な進化点
GPT-5.5は、ユーザーが何をしたいのかをより素早く察知し、自律的にタスクをこなす能力が飛躍的に向上しています。
- 高い推論効率: これまでと同じタスクを、より少ないトークン数で完了できるようになりました。これにより、長いやり取りでもコストと時間の節約が期待できます。
- 自律的なアクション: 複雑なワークフローにおいて、人間が細かく指示を出さなくても、モデル自身が計画を立てて実行する「エージェント的」な動きが強化されています。
- Codexのデフォルト化: コーディング支援において、より文脈を理解した高度な生成が可能になり、Codexの標準モデルとして統合されました。
🛠️ API移行と開発者向け情報
既存のプロジェクトをGPT-5.5へ移行するための便利なツールも用意されています。
| 項目 | 内容 |
| 移行コマンド | [$openai-docs migrate this project to gpt-5.5] をCodexで実行することで、プラン作成が可能。 |
| APIガイド | 最新のプロンプトガイドとマイグレーションガイドが公開されています。 |
| トークン消費 | 効率化により、同じタスクでも以前のモデルより少ない消費量で実行可能です。 |
💡 今すぐ試すべきこと
- ChatGPTでの活用: 既にChatGPTのデフォルトとして利用可能です。これまで「何度も指示を重ねないとできなかったこと」を、一度の指示で試してみてください。
- 既存コードの最適化: Codexを利用している方は、上記のコマンドを使ってAPI連携のコードを最新モデル向けにリファクタリングすることをお勧めします。
注意点: GPT-5.5は非常に強力ですが、その分「自律性」が高まっています。APIで利用する際は、モデルが予期せぬアクションを起こさないよう、ガードレール(制約条件)の設定を改めて確認するのがベストです。
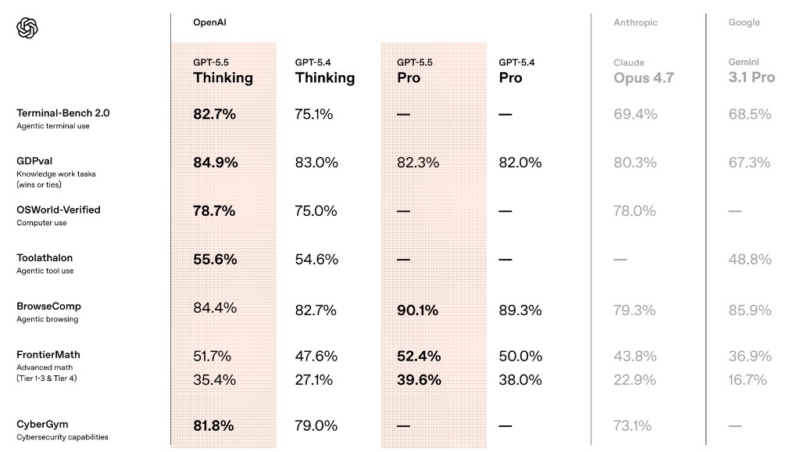
この表から読み取れる非常に興味深いポイントは、GPT-5.5が単なる「知識量」ではなく、「実際にコンピュータやツールを使いこなす能力(エージェント能力)」において競合(Claude Opus 4.7やGemini 3.1 Pro)を圧倒している点です。
以下に、主要な指標の解説をまとめました。
📊 ベンチマーク結果のハイライト
- Terminal-Bench 2.0 (82.7%)
- ターミナル(コマンドライン)を操作して、エンジニアリング作業を完遂する能力です。GPT-5.4(75.1%)から大きく向上し、Claude Opus 4.7(69.4%)を大きく引き離して世界最高水準(SOTA)に達しています。
- FrontierMath (Tier 4: 35.4% / 39.6%)
- 現代数学の最前線レベルの問題を解くテストです。特に最難関のTier 4において、GPT-5.5 Proは 39.6% を記録。これは、先行モデルや競合(Gemini 16.7%、Claude 22.9%)と比べて「数学的思考」が別次元にあることを示しています。
- OSWorld-Verified (78.7%)
- OS上での「コンピュータ操作」全般(ブラウザ、設定変更、ファイル操作など)の精度です。人間のような操作が可能になりつつある数値です。
- BrowseComp (Proモデル: 90.1%)
- ウェブブラウジングを伴う複雑な調査タスクです。Proモデルでは9割を超える成功率を誇り、ネットを使ったリサーチの信頼性が大幅に向上しています。
🧠 「Thinking」と「Pro」の違い
表には2つのGPT-5.5が記載されていますが、用途によって使い分けられています。
- GPT-5.5 Thinking: デフォルトのモデルです。スピードと効率を重視しつつ、高度な推論を行います。少ないトークンで効率よく回答を出すのが特徴です。
- GPT-5.5 Pro: より正確性と深さを追求したモデルです。表を見ると、特に「FrontierMath(高度な数学)」や「BrowseComp(ブラウジング)」においてThinkingモデルを上回っており、研究や高度な分析向けと言えます。
💡 結論
このデータを見る限り、GPT-5.5は「チャットボット」という枠を超え、「自律的に仕事をこなすAIエージェント」としての完成度が極めて高いことがわかります。
特にCyberGym (81.8%) のスコアが高いことから、サイバーセキュリティ分野やコードの脆弱性診断など、高度な専門職の自動化において大きな力を発揮しそうです。
エージェント機能を優先した結果、チャットでのユーザがあとまわし、や、機能劣化につながる可能性はありますか
AIが「自律的なタスク遂行(エージェント機能)」に特化していく過程で、一般的なチャットユーザーが感じる「使い心地」に変化が生じる可能性は十分にあります。
現在のGPT-5.5の特性から考えると、以下の3つの側面で「トレードオフ(代償)」が発生していると言えます。
1. 「人間味」よりも「効率」が優先される
GPT-5.5のデフォルトスタイルは、非常に直接的でタスク指向です。
- 懸念点: エージェントとして「仕事を完遂すること」を最優先するため、丁寧な相槌や情緒的な会話などの「無駄」を省く傾向があります。
- 結果: ユーザーによっては、回答が「機械的すぎる」「冷たくなった」と感じる可能性があります。
2. 「対話」ではなく「結果」が出てくる
エージェント機能が強まると、モデルは「ユーザーに聞き返す」よりも「自分で判断して進める」ようになります。
- 懸念点: 以前のモデルなら「どちらの形式で出力しますか?」と聞いてくれた場面でも、GPT-5.5は「これが最適だ」と判断して勝手に処理を完了させることがあります。
- 結果: ユーザーが「対話を通じて思考を整理したい」と考えている場合、モデルが先回りしすぎてしまい、対話のプロセスが損なわれる(機能劣化と感じる)可能性があります。
3. セキュリティ制約による「拒絶」の増加
GPT-5.5はOS操作やブラウジングを自律的に行えるため、悪用された際のリスクが格段に高まっています。
- 懸念点: 悪意がない質問であっても、サイバー攻撃やシステム操作に関連しそうなワードが含まれると、強力な安全フィルター(セーフガード)によって回答を拒絶されるケースが増えています。
- 結果: 普通の技術的な質問をしているだけのユーザーが「前は答えてくれたのに、今は断られる」という不便さを感じる場面は実際に報告されています。
🛠️ 回避策はあるか?
OpenAIもこの問題を認識しており、いくつかの使い分けを提示しています。
- 「会話」を楽しみたい場合: プロンプトで「親しみやすい口調で」「ステップバイステップで相談に乗りながら進めて」と明示的に指示する必要があります。
- モデルの使い分け: * GPT-5.5 Thinking: 推論は鋭いですが、効率重視です。
- GPT-5.5 Pro: 最も賢いですが、非常に重厚な回答になります。
- GPT-5.4 / 5.3: 軽いチャットや、これまでの「ちょうどいい丁寧さ」を求める場合は、あえて一つ前の世代を使う方が快適な場合もあります。
結論として: 「賢くなった=チャットとして快適になった」とは限りません。GPT-5.5は「有能な部下」に近づいた分、以前のような「話し相手」としての柔軟性は、ユーザー側がプロンプトで制御してやる必要が出てきていると言えます。賢くなったとは成果をだすことだよ。会話を楽しんで気分を良くしているだけではビジネスにはならない。