デジタル音声フォーマット、特にWAV形式の構造とその操作方法について解説しています。一方の資料は、ADPCM方式を用いた音声のエンコードおよびデコードの設計に関する研究報告であり、VHDLやVisual Basicを用いた具体的なアルゴリズムの実装プロセスを詳述しています。もう一方の資料は、Pythonのwaveモジュールに関する公式ドキュメントで、プログラムから非圧縮のPCMデータを読み書きするためのAPI仕様を定義しています。両者は共に、音声をデータとして扱うためのサンプリング理論やヘッダ情報の構成といった基礎知識を共有しています。全体として、音声信号を計算機上で処理・圧縮するための理論的背景と、実際の開発手法の両面をカバーする内容となっています。
音響解析実務ガイドライン:Librosaを用いた特徴量抽出と分析ワークフローの体系化
1. デジタルオーディオの物理的基礎と標本化理論
1.1 デジタル音響解析における「音」の物理的定義
音響解析を実務で扱う上で、まず理解すべきは「音」という連続的な空気圧変化(アナログ信号)を、いかに情報の欠落を最小限に抑えてデジタル化するかという戦略的判断です。デジタイズの精度は、その後のスペクトル解析や機械学習モデルの性能上限(アッパーバウンド)を決定づけます。物理現象としての音を理解せずして、信頼性の高い解析アルゴリズムを構築することは不可能です。
1.2 標本化(サンプリング)と量子化のメカニズム
アナログ信号からデジタルデータへの変換プロセスは、「標本化」と「量子化」の二軸で定義されます。
- 標本化(サンプリング)とシャノンの定理: 連続波形を時間軸に沿って一定間隔で抽出する工程です。標本化周波数(サンプリングレート)は、再現可能な上限周波数を規定します。**シャノンの定理(ナイキスト定理)**により、再現したい上限周波数の2倍以上のレートが必要となります。例えば、人間の可聴域上限である20kHzをカバーするために、音楽CDでは44.1kHzが採用されています。
- 量子化とダイナミックレンジの制約: 各サンプル点での振幅を数値化する工程です。量子化ビット数とダイナミックレンジには「1ビットあたり6dBの法則」が成立し、16bitでは理論上96dB、24bitでは144dBのレンジを確保できます。
- 実務上の重要点(8-bit vs 16-bit): 8-bit PCMは**符号なし(Unsigned)であり、無音状態が「128」として表現されます。一方、16-bit PCMは符号付き(Signed)**で、無音は「0」です。Librosa等のライブラリで8-bit WAVを処理する場合、そのままではDCオフセットが発生するため、解析前に128を減算して正規化する処理が不可欠です。これを怠ると、スペクトログラムの低域に偽のエネルギーが集中する原因となります。
1.3 WAVフォーマットの構造的解剖
WAVファイル(RIFF形式)のバイナリ構造を理解することは、トラブルシューティングにおいて必須のスキルです。
- RIFFヘッダ(Offset 0-3):
RIFFの4文字で始まり、直後のOffset 4-7にファイルサイズから8バイトを引いた値(RIFFペイロードサイズ)が格納されます。 - fmtチャンク: チャンネル数、サンプリングレート、量子化ビット数などのメタデータを含みます。フォーマットIDが
0x0001であれば無圧縮PCMを指します。 - dataチャンク: 実際の波形データが格納されます。
dataの識別子に続き、そのデータのサイズが記録されています。 - リトルエンディアン形式: WAVは複数バイトの整数を、下位バイトから順に配置するリトルエンディアンを採用しています。バイナリレベルでの修正やADPCM等のデコーダ実装時には、このバイトオーダの変換を誤るとデータが完全に破壊されます。
1.4 セクション結語
物理的制約(サンプリングレートによる帯域制限、ビット深度による分解能)は、特徴量抽出アルゴリズムの選定基準となります。特にハイレゾ音源(24bit/96kHz以上)を扱う場合は、フィルタリング設計における計算負荷と精度のトレードオフを慎重に評価する必要があります。
--------------------------------------------------------------------------------
2. Librosaによる音響特徴量の多角的抽出
2.1 特徴量抽出の役割と次元圧縮
音響信号は非常に高次元なデータ群です。特徴量抽出の本質は、信号の「意味」を損なわずに低次元の表現へと変換する「次元圧縮」にあります。目的(音声、音楽、異常音等)に応じて、時間・周波数・知覚のどのドメインを強調すべきかを決定します。
2.2 時間ドメイン指標の評価
- RMS (Root Mean Square): 瞬時値ではなく、一定期間の音圧エネルギー(平均的な盛り上がり)を評価します。楽曲の構成分析において、セクションごとのダイナミクス変化を捉えるのに有効です。
- Zero-crossing Rate (ZCR): 波形がゼロ交差する頻度を計測します。高域成分やノイズ性の判定、さらには無音区間の特定におけるインパクトの強い指標です。
2.3 周波数ドメイン指標の分析
- Spectral Centroid / Bandwidth: スペクトルの「重心」は音の明るさに、「帯域幅」は音の広がりに対応します。中域にエネルギーが集中しているか、広帯域に分布しているかを評価します。
- Spectral Flatness: スペクトルの平坦性を0〜1で評価します。1に近いほどホワイトノイズ的な性質を持ち、0に近いほど調波構造が複雑であることを示します。
- Spectral Rolloff / Contrast: 総エネルギーの85%が集中する周波数を特定するRolloffは、スペクトルの端部を把握するのに役立ちます。Contrastは帯域ごとの明瞭さを抽出し、音色のコントラストを評価します。
2.4 人間知覚に基づく高度な特徴量
- Melspectrogram & MFCC: 人間の聴覚が低域の変化に対して非線形(対数的)に敏感であるという特性に基づいた「メル尺度」を用います。
- MFCC(メル周波数ケプストラム係数): スペクトルの「概形(包絡線)」を抽出します。音声認識等ではデフォルトの
n_mfcc=20が一般的ですが、環境音や複雑な楽器音の解析では、より詳細な情報を保持するためにn_mfcc=40程度まで拡張することを検討すべきです。
- MFCC(メル周波数ケプストラム係数): スペクトルの「概形(包絡線)」を抽出します。音声認識等ではデフォルトの
- Chromagram (STFT, CQT, CENS, VQT): 周波数を12音階にマッピングします。
- STFT: 時間分解能を優先する場合。
- CQT (Constant-Q Transform): 音楽的な音階に対して等間隔なビンを持つため、和音推定において極めて強力な戦略的価値を持ちます。
- Tonnetz: 音楽理論的な和音構造(完全五度や長短三度の関係)を数値化し、楽曲のハーモニー変化を捉えます。
--------------------------------------------------------------------------------
3. 目的に応じた分析ワークフローの最適化
3.1 意思決定プロセスの重要性
解析精度を決定づけるのは、手法そのものよりも「目的に対する逆算」です。適切な特徴量の選定は、後続の機械学習モデルの学習効率を劇的に向上させます。
3.2 ユースケース別特徴量選定マトリクス
| 解析目的 | 推奨特徴量セット | 選定理由(エンジニアの視点) |
| 和音推定 (Chord) | Chromagram (CQT), Tonnetz | 12音階エネルギー分布と和音間の調和関係を物理・理論両面で抽出するため。 |
| 感情・音声認識 | MFCC (n=40), RMS | 声道の共鳴特性(スペクトル概形)と発話のダイナミクスを優先するため。 |
| 楽曲の構成分析 | Spectral Rolloff, RMS, Centroid | セクション境界(Aメロ→サビ等)での音色明度やエネルギーの「変化点」を検知するため。 |
| 異常検知・ノイズ判定 | Spectral Flatness, ZCR, Contrast | 信号の定常性崩壊や非定常な高域成分の発生を感度良く捉えるため。 |
3.3 スペクトログラム解析の深化:フィルタリングの重要性
実務上の差別化要因は、Librosaによる変換前の「前処理」にあります。
- Scipyを用いたフィルタリング: 標準的なFFTベースの解析では、DCオフセットや電源由来のハムノイズ、不要な低域振動が特徴量に混入し、精度を下げます。
- Pro-tip: 解析前にScipyの
scipy.signal.firwinやiirfilterを用いて帯域制限を行い、目的の倍音成分を隔離した上でメルスペクトログラムへ変換することで、ノイズ耐性の高い特徴量を生成できます。
--------------------------------------------------------------------------------
4. 解析ツールの実装アーキテクチャ:MVCモデルの適用
4.1 アーキテクチャ設計の戦略的価値
音響解析ツールでは、Librosaによる重い計算(Model)とMatplotlibによる描画(View)が密結合すると、解析中にUIがフリーズする致命的な欠陥が生じます。ロジックとインターフェースの分離は、実務的なツール開発において妥協できない要件です。
4.2 PySide(Qt)を用いた動的なインターフェース
- Qt Designer: ウィジェット配置をXML形式(.ui)で管理し、UIとロジックをファイルレベルで分離します。
- Signal/Slotメカニズム: 「スライダーの変更」というシグナルが、解析パラメータの更新スロットを叩くといったイベント駆動設計を採用します。
4.3 MVCの役割定義とオーディオ処理の最適化
- Model: Librosaを用いた信号処理ロジックを保持。計算完了時に
Signal(numpy.ndarray)を発行します。 - View: MatplotlibのCanvasをPySideウィジェットに埋め込み、Modelからのシグナルを
Slotで受け取り描画を更新します。 - Controller: ユーザー入力のバリデーション(例:
n_fftがサンプリングレートを超えないか等)を行い、ModelとViewの調停を担います。これにより、GUIの操作性を維持しつつ、背後でCPU負荷の高い計算を安全に実行可能です。
--------------------------------------------------------------------------------
5. 実務におけるトラブルシューティング:データ破損と修復
5.1 データ破損のリスクと技術的背景
録音の中断やシステムクラッシュ時、ファイルサイズは存在するのに再生できない事象は「ヘッダー情報の未書き込み」に起因します。WAVファイルは終了時にヘッダーを更新するため、強制終了するとRIFFサイズやdataサイズが初期値の0のまま残るためです。
5.2 破損の兆候と原因特定
- 0:00表示の怪: ファイルサイズ(KB/MB)があるにもかかわらず、OSが再生時間を0秒と認識する場合、データチャンクサイズフィールドの破損が濃厚です。
- 無効なRIFFヘッダー: ヘッダーの開始位置に適切なマジックナンバーが書き込まれていない状態です。
5.3 修復技術の階層的アプローチ
- AudacityによるRawデータのインポート: 最も堅牢な方法です。ヘッダーを無視して生のバイナリを読み取ります。サンプリングレート、ビット深度、バイト順(Little Endian)を手動指定することで、データを確実に救出できます。
- ffmpegによるコンテナ再構築:
ffmpeg -i corrupted.wav -ignore_length 1 repaired.wavのようにコマンドラインからヘッダーの長さを無視して再エンコードをかける手法です。 - バイナリレベルの精密修復 (Hex Editor): バイナリエディタを用い、以下の数式に基づいて32bitリトルエンディアン形式で値を書き込みます。
- RIFFペイロードサイズ(Offset 4):
実際のファイルサイズ - 8 - dataサイズ(dataチャンク識別子直後):
実際のファイルサイズ - データオフセット - 8これにより、厳格なバリデーションを行うDAW(Pro Tools等)でも再生可能な状態まで完全に回復させることができます。
- RIFFペイロードサイズ(Offset 4):
5.4 結語:完全性担保のためのベストプラクティス
データの完全性は、解析の信頼性の根幹です。録音時のForce Stop回避、高品質なストレージの選定、そして解析前のバックアップ作成を鉄則としてください。物理・心理の両面からアプローチする高度な特徴量抽出と、堅牢なMVCアーキテクチャによるツール構築が、音響データから真の知見を引き出す鍵となります。
WAVファイル構造解剖書:バイナリデータの深淵を解き明かす
1. イントロダクション:デジタルオーディオの「器」を知る
音響エンジニアリングの世界へようこそ。私たちが耳にする「音」は空気の振動という連続的なアナログ信号ですが、コンピュータでこれを扱うには、非連続なデジタルデータへと変換する「デジタイズ」の工程が不可欠です。このプロセスは、時間軸を細切れにする「標本化(サンプリング)」と、音の大きさを数値化する「量子化」の2ステップで成り立っています。
低レイヤの視点で最も重要なのは、次の2つの変数です。
- 標本化周波数(サンプリングレート): 1秒間に何回音を切り取るかを示します。音響学の基礎である「シャノン・ナイキストの定理」によれば、再現したい周波数の2倍以上の速さでサンプリングする必要があります。人間の可聴域上限とされる20kHzをカバーするために、CD規格では44.1kHzという数値が採用されています。
- 量子化ビット数(ビット深度): 切り取った音の大きさを何段階の数値で表現するかを決定します。ここでは「6dBルール(ダイナミックレンジ ≒ ビット数 × 6dB)」を覚えておきましょう。16bitなら約96dBのダイナミックレンジを確保でき、これはアナログレコード(約48dB)を遥かに凌駕する圧倒的な再現力を生み出します。
これらのメタ情報を正しく格納するための「器」がWAVファイルです。では、その内部構造をバイナリレベルで解剖していきましょう。
--------------------------------------------------------------------------------
2. WAVファイルの全体像:RIFFコンテナの三層構造
WAVファイルは、MicrosoftとIBMによって策定された「RIFF (Resource Interchange File Format)」という汎用コンテナ形式を採用しています。最大の特徴は、データを「チャンク(塊)」という単位で管理することです。
ファイルの先頭から、大きく分けて以下の3つの主要要素で構成されています。
| 要素名 | 役割 | 含まれる主な情報の例(CD音質の場合) |
| RIFFヘッダ | ファイルの識別とサイズ定義 | "RIFF"、全体サイズ、"WAVE"識別子 |
| fmtチャンク | 音声の書式(フォーマット)情報 | PCM形式ID、2ch、44.1kHz、16bit、ブロックサイズ |
| dataチャンク | 実際の波形データ | L/R各チャンネルの数値データの羅列 |
このように、WAVファイルは「これからどのような形式の数値が並ぶか」を先に宣言(メタ情報)し、その後に膨大な数値の羅列(波形データ)を配置する整然とした構造を持っています。
--------------------------------------------------------------------------------
3. RIFFヘッダとfmtチャンクのバイナリ解剖
バイナリエディタでWAVファイルを開くと、先頭の44バイト(標準的なPCMの場合)に重要な「取扱説明書」が書き込まれています。ソースコンテキストに基づく具体的なバイト配置を見てみましょう。
主要なバイナリ配置(44.1kHz / 16bit / ステレオの場合)
- "RIFF" 文字列(4バイト):
52 49 46 46 - ファイルサイズ(4バイト):
XX XX XX XX- この値は「ファイル全体のサイズから8バイト(RIFF識別子とこのサイズフィールド自体)を引いた値」を記録します。
- "WAVE" 文字列(4バイト):
57 41 56 45 - "fmt " 文字列(4バイト):
66 6D 74 20(末尾の半角スペースに注意) - fmtチャンクサイズ(4バイト):
10 00 00 00- 標準的なPCMの場合、ここには固定値の16(16進数で
10)が入ります。
- 標準的なPCMの場合、ここには固定値の16(16進数で
- フォーマットID(2バイト):
01 000x0001は「非圧縮のリニアPCM」であることを示します。
- サンプリングレート(4バイト):
44 AC 00 00(44,100Hz) - ブロックサイズ(2バイト):
04 00- 1サンプルあたりのバイト数(ステレオ16bitなら 2ch × 2byte = 4byte)です。パーサの実装には必須の情報です。
- 量子化ビット数(2バイト):
10 00(16bit)
[!TIP] So What?(学習者への洞察:リニアPCMの価値) なぜこのような厳格な構造が必要なのでしょうか。それは、WAVが採用する「リニアPCM」が、音を単純な「数値の配列」として扱うからです。この構造を理解していれば、デコード処理なしでバイナリを直接読み取り、数学的な演算(加算によるミキシング、乗算による音量変更など)を即座に適用できるのです。
--------------------------------------------------------------------------------
4. リトルエンディアン:データの「逆さま」な並び順
WAVファイルを解析する開発者が最初に直面する壁が「リトルエンディアン」です。これは、複数バイトで構成される数値を記録する際、「位の低いバイト(下位バイト)を、番地が小さい方(先頭)」に置くというルールです。
視覚的な分解例:サンプリングレート 44100
- 10進数: 44100
- 16進数(4バイト/DWORD):
00 00 AC 44 - WAVファイルでの並び:
44 AC 00 00
ここで注意すべきは、データ型による解釈の違いです。量子化ビット数のような2バイト(WORD)値と、サンプリングレートのような4バイト(DWORD)値が混在しているため、バイナリエディタで読む際は「何バイトを一区切りとして逆転しているか」を常に意識しなければなりません。
--------------------------------------------------------------------------------
5. 波形データの並びと「無音」の数値特性
"data"識別子の後には、いよいよ波形の正体であるバイナリの羅列が続きます。
チャンネルの並び
ステレオデータの場合、サンプルは 「L, R, L, R...」 と、時間順に左右が交互にインターリーブ(交差配置)されて記録されます。
8bit vs 16bit の数値構造と「無音」
ビット数によって、波形の中心(無音状態)の表現方法が根本的に異なる点に注目してください。
| 特性 | 8bit PCM | 16bit PCM |
| 符号の有無 | 符号なし(Unsigned) | 符号あり(Signed / 2's Complement) |
| 数値の範囲 | 0 〜 255 | -32768 〜 32767 |
| 無音時の数値 | 128(バイアスあり) | 0(センターポイント) |
8bit PCMは「128」を中心として上下に振れるバイアス方式ですが、16bit PCMは「0」を中心としてプラスとマイナスに振れるバイポーラ方式です。この違いを理解していないと、プログラムで音声を合成した際に、16bitデータを8bitとして扱ってしまい、激しいノイズを発生させる原因となります。
--------------------------------------------------------------------------------
6. まとめ:構造を理解した先にあるもの
WAVファイルの構造を知ることは、デジタルオーディオを「ブラックボックス」から「制御可能な対象」へと変える第一歩です。この知識は、単なる再生ソフトの作成に留まらず、次のような実戦的な場面で力を発揮します。
- 破損ファイルの修復: 録音中に電源が落ち、RIFFサイズやdataサイズが「0」のまま未完成となったファイルも、バイナリエディタで正しい値を書き込めば蘇ります。
- 信号処理(DSP)の自作: ライブラリに頼らず、生のバイナリ配列を直接計算してフィルタリングやエフェクトを実装できます。
学習のチェックリスト
- [ ] ファイル先頭に "RIFF" と "WAVE" のマジックナンバーがあるか?
- [ ] 44.1kHz(
44 AC 00 00)のような数値がリトルエンディアンで読めるか? - [ ] 16bit PCMの無音データが「0」で埋まっていることを確認したか?
- [ ] fmtチャンクのサイズが
10 00 00 00(16バイト)であることを理解したか?
次は、Pythonの wave モジュールや numpy を使って、実際にこのバイナリの海を操作するスクリプトを書いてみましょう。構造を掴んだあなたにとって、それはもはや難しいことではありません。デジタルオーディオの深淵へ、自信を持って踏み出してください。
音のデジタル化ハンドブック:アナログの波が「データ」に変わる仕組み
1. はじめに:音の正体と「デジタイズ」の魔法
私たちは普段、空気の振動を「音」として感じ取っています。この空気の振動は、途切れのない滑らかな曲線で描かれるアナログ信号です。しかし、コンピュータはこのような連続的な変化をそのまま扱うことができません。
そこで必要になるのが、音をコンピュータが理解できる「0」と「1」の不連続な数値データに置き換えるプロセス、**「デジタイズ(デジタル化)」**です。
イメージとしては、滑らかな「坂道(アナログ)」を、カクカクとした「階段(デジタル)」に作り変えるようなものです。遠くから見れば元の坂道に見えますが、近くで見ると細かな数値の集まり(点グラフの連続)になっています。この変換を正確に行い、再び美しい音として蘇らせるためには、厳密な「データの設計図」が必要になります。その魔法の裏側にあるルールを、次章から紐解いていきましょう。
--------------------------------------------------------------------------------
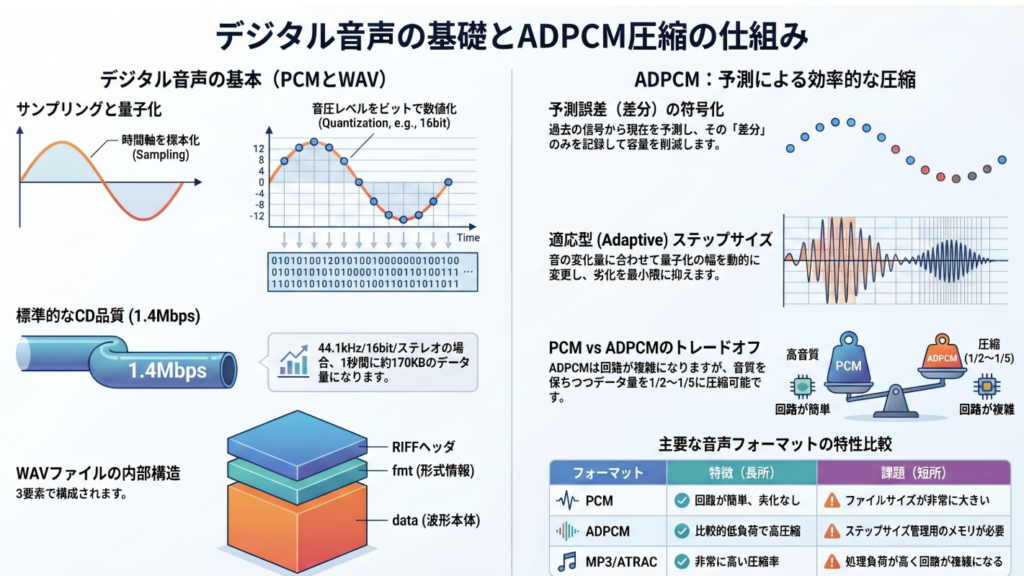
2. デジタル化の2大要素:標本化(サンプリング)と量子化
音をデジタル化する際、どれだけ精巧な「階段」を作るかを決めるのが、標本化と量子化という2つの要素です。
標本化(サンプリングレート)
- 意味: 音圧レベルを測定する「時間的な周期」のことです。1秒間に何回シャッターを切るか、という時間軸の細かさを表します。
- 深掘り: 音楽CDでは44.1kHz(毎秒44,100回)という数値が使われます。これは「再現したい周波数の2倍以上の頻度で測定すれば、元の波形を復元できる」というシャノンの定理に基づいています。人間の可聴範囲の上限である20kHzをカバーするため、余裕を持ってこの数値が採用されています。
量子化(ビット数)
- 意味: 測定した音の大きさを、何段階の数値で表現するかという「縦方向の解像度」のことです。
- 深掘り: 16ビットの場合、音の強弱を 2^{16} = 65,536 段階で表現します。デジタル音響には**「1ビット増えるごとにダイナミックレンジ(扱える音の幅)が6dB広がる」**という法則があります。16ビットなら 16 \times 6 = 96\text{dB} となり、アナログレコード(約48dB)を圧倒します。
- さらなる高みへ: 人間の聴覚は最大120dB程度の幅を感知できると言われており、16ビット(96dB)は「十分」ではあっても「完璧」ではありません。より原音に近い感動を追求するDVDオーディオなどの「ハイレゾ音源」で24ビット(144dB相当)が使われるのは、この聴覚限界を超えるためなのです。
視覚的まとめ:デジタル化のグリッド構造
音をデジタル化するとは、音の波を「時間」と「精度」の格子(グリッド)の中に閉じ込める作業です。
| 要素 | 軸 | 例(CD品質) | 役割 |
| 標本化周波数 | 横軸(時間) | 44.1kHz | 再現できる「音の高さ(周波数)」を決める |
| 量子化ビット数 | 縦軸(精度) | 16bit | 音の「解像度・強弱の幅」を決める |
これらの設定を高くするほど音は美しくなりますが、その代償として「データサイズ」も増大します。
--------------------------------------------------------------------------------
3. 無圧縮の王道:PCM(パルス符号変調)方式
**PCM(Pulse Code Modulation)**は、サンプリングして得られた測定値をそのまま記録する方式です。「加工を施さない、最も正直なスナップ写真」のようなものだと考えてください。
データサイズの計算
CD品質(44.1kHz / 16bit / ステレオ)のデータが1秒間にどれくらいの容量になるか計算してみましょう。
\text{44,100 (Hz)} \times \text{16 (bit)} \times \text{2 (ch)} = 1,411,200 \text{ bps} \approx 1.4 \text{ Mbps}
これをバイト換算すると、1秒間で約170KBになります。たった数分の曲でも、積み重なれば巨大な容量になります。
PCMのメリットと課題
- メリット
- 音質の劣化がない: 測定値をそのまま保存するため、理論上、最も原音に忠実です。
- 回路がシンプル: 複雑な展開処理が不要なため、再生システムの構築が容易です。
- デメリット
- ファイルサイズが巨大: 圧縮を行わないため、保存ストレージや通信帯域を圧迫します。
この「巨大なデータ」を、音質を保ちつつ賢くスリムにするための知恵が、次に紹介する「予測」の技術です。
--------------------------------------------------------------------------------
4. 予測で容量を削る:ADPCM(適応差分PCM)の知恵
ADPCM(Adaptive Differential Pulse Code Modulation:適応差分PCM)は、一言で言えば**「未来を予測して、そのズレだけを記録する賢い仕組み」**です。
圧縮の核心メカニズム
- 相関性の利用: 音の波形は急激に飛ぶことは少なく、直前のデータと似ている(相関がある)という性質を持っています。
- 差分(予測誤差)の記録: 数値をそのまま記録する代わりに、「前の値からどれだけ動いたか」という差分のみを量子化します。これにより、本来16bit必要な情報を3〜8bitまで大幅に削減できます。
- 適応(アダプティブ): 音の変化の激しさに応じて、変化を測る「ものさし(ステップサイズ)」をリアルタイムに調整します。
- 技術的な裏側: 具体的には、**8から32,767まで「88段階」もの細かなステップサイズ(ものさし)**を使い分け、変化が激しい時は大きく、静かな時は細かく測定することで、圧縮しても音の輪郭を損なわないように工夫されています。
ADPCMは、計算によってデータの重複を削ぎ落とす「知恵の圧縮」なのです。
--------------------------------------------------------------------------------
5. 徹底比較:PCM vs ADPCM
「音の美しさ」と「データの軽さ」のどちらを取るべきか。その答えは用途にあります。
| 項目 | PCM(無圧縮) | ADPCM(圧縮) |
| 圧縮の有無 | なし | あり(非可逆) |
| データ量 | 非常に大きい | 小さい(PCMの約1/2〜1/5) |
| 音質の劣化 | なし | わずかにあり |
| 実用上の評価 | 究極の再現性 | 4bit時でも16bit PCMと遜色ない聴感 |
| 主な用途 | 音楽制作、マスター音源 | 通信、ゲーム、容量節約 |
初心者のための用途別ガイド
- 「1ミリも音質を妥協したくない、編集もたっぷりしたい」なら:PCM
- 「音質は16bit並みに保ちつつ、容量を1/4に抑えてコスパ良く楽しみたい」なら:4ビットADPCM
これらのデータは、最終的に「WAV」という器に大切に収められます。
--------------------------------------------------------------------------------
6. データの器:WAVフォーマットとヘッダ情報
Windowsなどで標準的な「WAVファイル」は、単なるデータの塊ではありません。例えるなら**「ラベルの貼られた標本瓶」**のような二層構造をしています。
- ヘッダ(設定情報): 瓶のラベルにあたる「再生プレイヤーへのささやき」です。「サンプリングレートは44.1kHz、16bitステレオですよ」といった説明書が書き込まれています(標準44バイト)。これがないと、プレイヤーは音を再現できません。
- データ(波形の実体): ラベルに従って並んでいる、数値データの列です。
データの裏側:リトルエンディアンと無音の定義
WAVには、私たちが普段意識しない面白いルールが隠されています。
- リトルエンディアン: 2バイト以上の数値を扱う際、「桁の小さい方(下位バイト)」から順に並べるという約束事です。
- 「無音」の意外な違い: 実はビット数によって、無音を表す数値が異なります。
- 8ビットPCM: 符号なし(0〜255)。**128が「無音」**の中心となります。
- 16ビットPCM: 符号付き(-32,768〜+32,767)。**0が「無音」**となります。 このルールの違いを知ると、バイナリエディタでデータを見たときに「なぜ無音なのに数値が並んでいるのか」という謎が解けます。
--------------------------------------------------------------------------------
7. まとめ:音をデジタルで操るために
音のデジタル化とは、目に見えない空気の震えを、緻密な計算とルールによって数値の芸術へと変換するプロセスです。
- デジタル化は**「時間(標本化)」と「精度(量子化)」**という2つのグリッドを組み合わせることで、アナログの滑らかさに迫ります。
- ADPCMは、88段階のステップサイズを使い分ける「予測」の知恵によって、データ量を劇的に減らしつつ、16bit PCMに迫る実用的な音質を実現しています。
この基本原理を理解すれば、スマートフォンの音楽アプリも、プロのレコーディング現場も、すべてはこの「0」と「1」の魔法で繋がっていることが実感できるはずです。デジタルオーディオの深遠な世界へ、ようこそ!
ADPCMコーデック技術実装仕様書:16bit PCMからの高効率圧縮とマルチプラットフォーム実装
1. はじめに:ADPCM方式の戦略的意義
現代の組み込みシステムにおいて、音声データの効率的な管理は、リソース制約とユーザー体験を両立させるための最重要課題の一つである。本仕様書は、16bit PCM(パルス符号変調)を3bitから8bitへ圧縮するADPCM(Adaptive Differential Pulse Code Modulation:適応差分PCM)方式の実装を定義する。
ADPCMは、過去の信号から現在値を予測し、その予測誤差(差分)のみを量子化する。汎用プロセッサ上でのソフトウェア実装(例:Athlon 1.5GHz環境)では、ステレオ処理において実時間の約20倍もの演算時間を要することが確認されており、リアルタイム性能の確保にはハードウェア資源を最適化した実装が不可欠である。本仕様は、演算負荷の高い乗算をビットシフトに置き換えるなど、FPGAやASICへの実装を前提とした高効率なアーキテクチャ設計を目的としている。
他フォーマットと比較した場合、ADPCMはMP3やATRACのような大規模な演算回路や作業用メモリを必要とせず、PCM単独よりも劇的にデータ量を削減できる。この「低回路規模」と「聴感上の音質維持」のバランスこそが、リソース制約の厳しい現場におけるADPCMの戦略的優位性である。
2. ADPCMアルゴリズムの理論と量子化ロジック
ADPCMの本質は、信号の動的な変化に追従する「適応的なステップサイズ制御」にある。
ステップサイズの計算ロジック
量子化の基準となるステップサイズは、最小値8から最大値32767までの88段階で構成される(表4-1参照)。このインデックス(アドレス)の増減により、信号の急峻な変化や静止状態を動的に捉える。入力された量子化コードに基づくインデックス修正値(K)は、以下の表に従って厳密に定義される。
表:インデックス修正値(K)の定義
| 入力コード(上位ビットからの判定) | 4bit以上実装時の修正値 K | 3bit実装時の修正値 K |
| 0000~0011 (正) / 1000~1011 (負) | -1 | -1 (コード 00, 01, 10, 11に相当) |
| 0100 (正) / 1100 (負) | +2 | +2 (コード 10/110) |
| 0101 (正) / 1101 (負) | +4 | +4 (コード 11/111) |
| 0110 (正) / 1110 (負) | +6 | - |
| 0111 (正) / 1111 (負) | +8 | - |
量子化とデコードの数学的定義
エンコード時、現在の予測値(GENZAI)と入力値の差分 D から量子化コード X を求める計算式は以下のように定義される。
X = \frac{D \times 2^{N-2}}{stepsize} (N は圧縮ビット数)
デコード時の出力(decode)は、前回の出力値(old)に算出された差分成分(sabun)を累積することで復元される。
decode = old + sabun
ここで、sabun は量子化コードの各ビットとステップサイズの組み合わせにより、以下の累積和として算出される。
sabun = \sum_{k=1}^{N-1} (stepsize_{stadr} \times 2^{-k} \times L_{N-k-1}) + (stepsize_{stadr} \times 2^{-(N-1)})
このロジックは、複雑な除算を必要とせず、リソース制約下でのビットシフト演算への置換を可能にしている。
3. WAVフォーマットとリトルエンディアン規則
ADPCMデータをWindows標準のWAVコンテナへ格納する際は、RIFF規格に準拠した正確なヘッダ構造とバイト順序の遵守が要求される。
ヘッダ構造のバイト単位定義
以下の表に基づき、各チャンクをリトルエンディアンで構成しなければならない。
表:WAVヘッダ構造仕様
| オフセット | サイズ | 内容 | 期待値 / 例 |
| 0x00 | 4 Byte | RIFFヘッダ | 'RIFF' (52 49 46 46) |
| 0x04 | 4 Byte | ファイルサイズ-8 | 全データ長に応じた値 |
| 0x08 | 4 Byte | WAVEヘッダ | 'WAVE' (57 41 56 45) |
| 0x0C | 4 Byte | fmtヘッダ | 'fmt ' (66 6D 74 20) |
| 0x14 | 2 Byte | フォーマットID | 0x0011 (IMA/DVI ADPCM) |
| 0x16 | 2 Byte | チャンネル数 | 0x0001 (Mono) / 0x0002 (Stereo) |
| 0x18 | 4 Byte | サンプリングレート | 例: 44100Hz (44 AC 00 00) |
| 0x22 | 2 Byte | 量子化ビット数 | 0x0010 (16bit) 等 |
| 0x24 | 4 Byte | dataヘッダ | 'data' (64 61 74 61) |
16bit PCMは符号付き(signed)整数(-32768〜32767)であり、上位バイトと下位バイトの順序が入れ替わるリトルエンディアン規則を誤ると、再生時に壊滅的な波形歪み(ノイズ)が発生するため、実装時には細心の注意を払うこと。
4. ソフトウェア実装仕様:Visual Basicによるコーデック開発
ソフトウェア実装は、主にアルゴリズムの整合性検証とビットパーフェクトな期待値の生成を目的とする。
エンコード/デコード処理の要勘所
- 初期化: ステップサイズ配列(88段階)をロードし、初期インデックスを1に設定する。
- ループ処理: 16bit PCM値から現在の予測値を減じ、量子化コードを生成。その後、上記2章の計算式に基づき予測値を更新する。
- オーバーフロー対策: 復元されたデコード値が16bit符号付き整数のダイナミックレンジを超えないよう、クリッピング処理を行う。ソースには
37267という数値の記述も見られるが、標準的な仕様としては -32768から32767 の範囲に固定することが厳守されるべきである。
実運用において、Visual Basic等の高レイヤー言語でのファイル入出力処理は、10進数変換の手間やCPUオーバーヘッドにより、リアルタイム性能が著しく損なわれる。ソフトウェアはあくまで「設計検証用」として位置づけ、本番運用にはハードウェア実装を推奨する。
5. ハードウェア実装仕様:VHDLによる回路設計
FPGA等へのハードウェア実装では、並列演算能力を活用し、ソフトウェアでのボトルネックを解消する。
回路設計と演算の最適化
VHDLによる同期式回路設計では、内部変数 SAB、STEPADR、GENZAI をクロックに同期して更新する。特筆すべきは、乗算をビットシフト演算に置換するロジックである。 ソースにおける ZERO(I-3 downto 0) & STEP(15 downto I-2) という記述は、ステップサイズに対する「2のべき乗での除算」を意味しており、これらを加算器と組み合わせることで、回路規模を大幅に抑制しつつ高速な積和演算を実現している。
実装上の注意点と検証
シミュレーション結果(図4-2, 5-2)からは、入力信号(IN)に対してデコード出力(ADPCM/syuturyoku)が数クロックで追従し、誤差が収束するプロセスが確認できる。 しかし、FPGA化における失敗事例として「メモリ関係のエラー」が報告されている。これはステップサイズ表をROMとして実装する際のタイミング制約やアクセス遅延に起因することが多い。アーキテクトとしては、ROM読み出しと演算のパイプライン設計において、十分なセットアップ/ホールド時間を確保する設計を指示する。
6. 技術的総括と性能評価
本仕様書に基づき実装されたADPCMコーデックの性能は、以下の分析結果に基づき評価される。
- 波形再現性: 無圧縮16bit PCMと比較し、高音域(変化の激しい成分)の再現性は非常に高い。一方で、量子化誤差の影響により低音域に一部損失が見られる。
- 圧縮ビット数の最適解: 実験データによれば、4bit圧縮と8bit圧縮の間で信号再現性の顕著な差は認められなかった。この結果から、「圧縮率と品質のバランスが最大化される4bit」を標準設計として採用すべきであると強く推奨する。3bit以下では音質劣化が顕著となり、用途が限定される。
- 今後の拡張性: 無音区間のデータ削減を目的としたランレングス方式(RLE)の併用は、さらなる効率化に有効である。ただし、ハードウェア実装においてはバッファリングによる入出力タイミングの不整合を防ぐため、FIFOメモリの導入を検討されたい。
結論として、本ADPCMコーデックは、リソース制限下における音声処理の基幹技術として、現代の組み込みシステムに最適化された信頼性の高いソリューションを提供するものである。
音の波を「予測」する技術:WAVとADPCMに学ぶデジタル音声の驚くべき裏側
1. イントロダクション:デジタル音声という「魔法」への招待
私たちがスマートフォンやPCで日常的に耳にしている音楽。その正体は「空気の振動」という形のないエネルギーを、「数字の羅列」に置き換えたものです。アナログからデジタルへの変換は、一見すると情報の断絶のように思えますが、そこには数学と知覚心理学が融合した、極めて精緻な「魔法」が隠されています。
この変換プロセスを直感的に理解するなら、「連続した滑らかな曲線の上に、細かな棒グラフを描き込んでいくイメージ」と言えるでしょう。一定の時間間隔で音の高さ(振幅)を測定し、その瞬間の値を階段状のデータとして固定する。この「デジタイズ」の裏側を知ることで、私たちが当たり前のように消費している「音」の深淵が見えてきます。
2. 【驚き1】WAVファイルは「自己紹介」から始まる:RIFFヘッダの正体
WAVファイルは単なる波形データの塊ではありません。ファイルの先頭には、そのファイルが何者であるかを示す「履歴書」や「地図」に相当する「ヘッダ情報」が格納されています。この「自己紹介」が正しく行われない限り、コンピュータは音を再生することすらできません。
ソースによれば、標準的なPCM形式のWAVファイルは「RIFF」という大きなコンテナの中に、以下の主要な4つの要素(チャンク)を含んでいます。
- RIFFヘッダ: ファイルの先頭4バイトに「RIFF」と刻まれ、これがRIFF形式のファイルであることを宣言します。
- WAVEヘッダ: 内部のデータが音声フォーマット(WAVE)であることを識別させます。
- fmtチャンク: サンプリングレートやチャンネル数など、音の再現に必要なスペックが記されています。
- dataチャンク: 実際の波形データのサイズと、それに続くデータ本体の開始位置を示します。
ここで音声システムアーキテクトとして興味深い「裏側」を一つ紹介しましょう。実は、量子化ビット数によって「無音」の定義が異なります。
- 8ビットPCM: 「符号なし(unsigned)」で処理され、0〜255の範囲をとります。この場合、**「128」が中心(無音)**となります。
- 16ビットPCM: 「符号付き(signed)」で処理され、-32,768〜+32,767の範囲をとります。この場合、**「0」が中心(無音)**となります。
このように、ビット深度によってデータの解釈そのものが根本から変わる設計になっているのです。
3. 【驚き2】「差分」を追えば音は縮む:ADPCMの予測マジック
データ量を抑えつつ、高い音質を維持するための巧妙な技術が「ADPCM(適応差分PCM)」です。一般的なPCMが各瞬間の値をそのまま記録するのに対し、ADPCMは「過去の値から現在の値を予測する」というアプローチをとります。
ソースには、ADPCMの動作原理が次のように記されています。
「音声信号のサンプル値の間には相関があり、過去の入力信号から現在の入力信号を予測することが可能であるという特徴を利用して、予測誤差を量子化している」
波形は急激に変化せず、直前のデータと強い関連性を持つという性質を利用し、「予測と実際の値のズレ(誤差)」だけを記録するのです。これにより、本来16ビット必要な情報を4ビット程度にまで圧縮できます。
特筆すべきは、その効率性です。単にデータが軽くなるだけでなく、**「同じビット数で比較した場合、ADPCMは通常のPCMよりも音質が良くなる」**という特性を持っています。回路構成は複雑になりますが、この「予測」という概念こそが、限られたリソースで豊かな音を届けるための鍵なのです。
4. 【驚き3】なぜCDは「44.1kHz」なのか?:シャノンの定理という限界線
音楽CDの標準スペック「44.1kHz / 16ビット」は、人間の生理的限界と数学的必然性の交差点です。
人間の可聴域は一般に20Hz〜20kHzとされています。数学的な「シャノンの定理(標本化定理)」に基づき、20kHzの音をデジタルで再現するには、その倍以上のサンプリング周波数が必要です。44,100Hzという数字は、この定理を満たしつつ、余裕を持たせた設計の結果です。
また、16ビットという精度は、音の強弱の幅(ダイナミックレンジ)を決定します。
- 計算根拠: 1ビットにつき約6dBの範囲を持つため、16ビットでは「16 × 6dB = 96dB」となります。
これはアナログレコードの約48dBを圧倒しますが、人間の知覚は最大120dB程度まで感知できるという説もあります。私たちが「ハイレゾ(24ビット=144dB)」を求めるのは、この「人間の耳とCD品質のわずかな隙間」を埋めるための飽くなき探究心ゆえなのです。
5. 【驚き4】壊れた音は「16進数」で蘇る:データ修復の舞台裏
録音中に電源が切れた際、WAVファイルが再生不能になることがあります。これは音声データそのものが壊れたのではなく、ヘッダ内の「サイズ情報」を書き込む前にファイルが閉じられてしまったことが原因です。
この場合、バイナリエディタで16進数データを直接書き換えることで、ファイルを「蘇生」させることが可能です。
【手動修復のステップ】
- 実ファイルサイズの確認: プロパティから、ファイル全体のバイト数を調べます。
- ペイロードサイズの計算: ヘッダに書き込むべき値は、**「ファイルサイズ - 8バイト」**です。
- リトルエンディアンでの書き換え: オフセット「0x04」付近の領域を書き換えます。
- ※リトルエンディアンとは、**「下位のバイトから順に並べる」**方式です(例:0x1234を「34 12」と書く)。
プロの現場では、この数バイトの修正だけで、数時間の録音データを救い出すことがあるのです。
6. 【驚き5】音を「見る」ための技術:Librosaと視覚化の力
現代の音声解析では、Librosaのようなライブラリを使って音を視覚化します。ここで重要なのが「メル尺度(Mel Scale)」です。
人間は、低域の音の変化には敏感ですが、高域(例えば20kHz付近)の微細な違いには驚くほど鈍感です。44.1kHzという高いレートでサンプリングしながら、知覚的には高域を識別できないという「シャノンの定理とメル尺度のアイロニー(皮肉)」を、コンピュータは巧みに利用しています。
Librosaで抽出される特徴量は、楽曲の「印象」と次のようにリンクしています。
- RMS(二乗平均平方根): 音の持続的な強さ。楽曲の**「盛り上がりや音圧」**と相関します。
- ゼロ交差率(Zero-crossing Rate): 波形が0を横切る頻度。値が高いほど**「高周波成分やパーカッシブなノイズ」**を含みます。
- スペクトル重心(Spectral Centroid): スペクトルの中心点。音のエネルギーの**「重心」**を示し、音の明るさを判断する指標になります。
結論:波形(Waveform)の未来へ
デジタル音声の技術は、古典的なADPCMから最新のAI解析まで、「いかに効率よく未来の波形を予測するか」というテーマで貫かれています。ADPCMが過去のデータから次の1サンプルを予測したように、現代のAIは膨大な学習データから「次に続くべき音」を生成し、失われた音質すら補完しようとしています。
もし私たちが音を「固定された数値」としてだけでなく、その「予測される未来の波」として捉え直したとき、音楽の聴き方はどう変わるでしょうか? 技術の裏側にある「予測のロジック」を知ることは、音という魔法の真実をのぞき見ることと同義なのです。