ローカルコンテナ(Docker)を使って自分だけのAI環境を構築するのは、データのプライバシーを守りつつ、さまざまなモデルを自由に試せる素晴らしいアイデアですね。
2026年現在、最も効率的で推奨される構築パターンを、目的別に3つご紹介します。
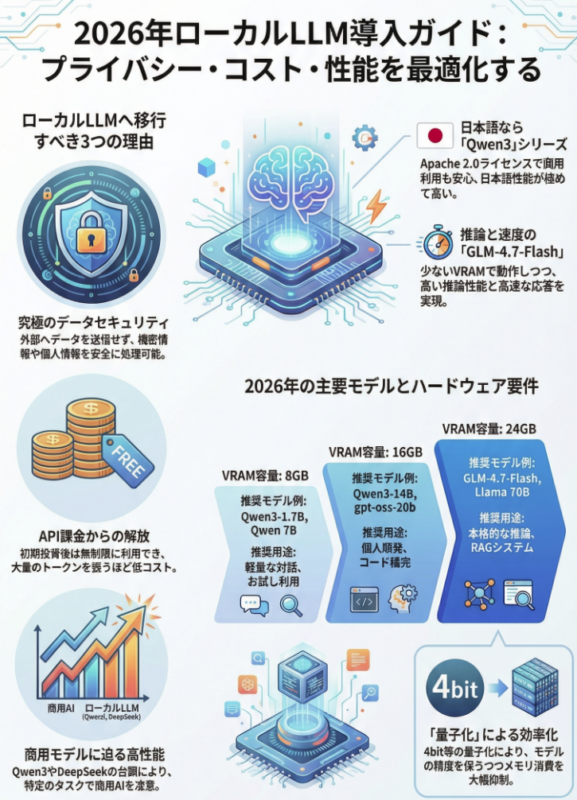
1. 最も手軽:Ollama + Open WebUI 構成
「とにかくChatGPTのようなチャット画面をローカルに作りたい」場合に最適です。
- 特徴: ブラウザから操作可能。Llama 3やMistralなど、最新モデルを1コマンドで追加できます。
- 構築手順:
docker-compose.yamlファイルを作成し、以下の内容を記述してdocker compose up -dを実行します。
services:
ollama:
image: ollama/ollama
volumes:
- ./ollama:/root/.ollama
ports:
- "11434:11434"
deploy: # GPUを使う設定(NVIDIA環境の場合)
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
open-webui:
image: ghcr.io/open-webui/open-webui:main
ports:
- "3000:8080"
environment:
- OLLAMA_BASE_URL=http://ollama:11434
volumes:
- ./open-webui:/app/backend/data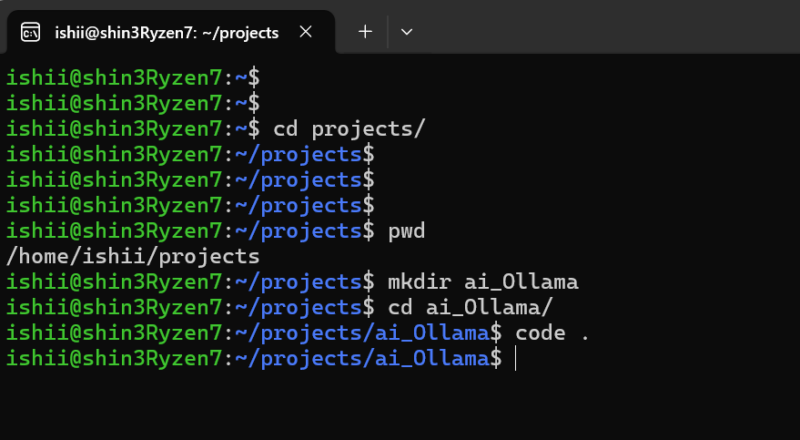
WSL2を起動して、私の場合にはコンテナはプロジェクト単位に/home/ishii/projectsの下にディレクトリをつくります。
そこで、Visual Studio Codeを起動します。 コマンドでは codeコマンドです。ちなみに、マイクロソフトって長年、このVisual なんとかってなまえできているけど、Visual Basicとか Visual C++とかの時代からで、ついVisual Source Safeとかいっちゃうわけです。わかる人は古い人
さて、VSCを起動して、docker-compose.yamlを作成して、ビルド&起動します。docker compose でupオプションで -dは、バックグラウンド起動です。
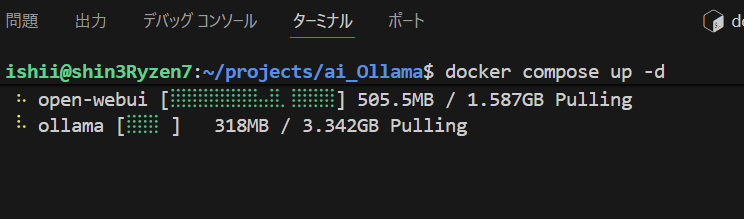
あわせて20GB弱ですから、けっこう時間はかかりますね。わたしのところで10分くらいかな。


管理者アカウントを作成してログイン
📥 モデルのダウンロード手順
- 設定画面を開く
- 画面左下にある自分の ユーザー名(またはアイコン) をクリックします。
- 表示されたメニューから 「Settings(設定)」 を選択します。
- 接続設定を確認する
- 設定内の左メニューから 「Connections(接続)」 を選びます。
- 「Ollama API」の項目があり、接続先が
http://ollama:11434(または前述のcompose設定通りのURL)になっていて、右側の更新ボタン(くるっとした矢印)を押して接続成功のチェックが出れば準備OKです。
- モデル名を指定してプル(ダウンロード)する
- 同じ画面、または 「Models」 セクションに、「Pull a model from Ollama.com」 という入力欄があります。
- そこに、使いたいモデル名を入力します。
- 例:
llama3.1 - 例:
phi3 - 例:
gemma2
- 例:
- 入力欄の右側にある ダウンロードボタン(雲のアイコンなど) をクリックすると、ダウンロードが開始されます。
- チャットで使用する
- ダウンロードが完了(Successと表示)したら、設定を閉じます。
- チャット画面上部の 「Select a model(モデルを選択)」 をクリックすると、今入れたモデルが表示されるので、それを選択すれば会話を始められます。
💡 どのモデル名を入れるべきか迷ったら
Ollama公式サイトのモデルライブラリ で、現在利用可能なモデル名の一覧を確認できます。
RTX 4070 Ti (VRAM 12GB) をお持ちなので、まずは以下のモデルを試すのがおすすめです。
llama3.1: 迷ったらこれ。非常に高性能で汎用性が高いです。gemma2:9b: Google製。日本語の扱いが比較的得意です。
Open WebUIの設定画面(画像2枚目)で「どこからダウンロードするか」ですが、「管理者設定」 という別の専用メニューから行います。
📥 モデルのダウンロード手順
- 「管理者設定」を開く
- 画面左下にある自分のユーザー名をクリックし、メニューから 「管理者設定 (Admin Settings)」 を選択します。
- ※通常の「設定」ではなく、必ず「管理者設定」の方を開いてください。
- 「設定」内の「モデル」タブへ移動
- 管理者設定画面が開いたら、左側のメニューから 「設定 (Settings)」 を選び、さらに上部のタブから 「モデル (Models)」 をクリックします。
- モデル名を入力してプル(ダウンロード)する
- 「Ollama.comからモデルをプル (Pull a model from Ollama.com)」 という入力欄があります。
- そこに、使いたいモデル名を正確に入力します。
- 例:
llama3.1 - 例:
gemma2:9b(日本語に強いのでおすすめ)
- 例:
- 入力欄の右側にある ダウンロードボタン(下矢印や雲のアイコン) をクリックすると、ダウンロードが開始されます。
- チャット画面で選択する
- ダウンロードが完了したら、元のチャット画面に戻ります。
- 画面上部の 「モデルを選択」 ドロップダウンに、今ダウンロードしたモデルが表示されるので、それを選択すれば会話を始められます。
🏎️ 今の環境(RTX 4070 Ti)をさらに使いこなすコツ
私の環境は12GBのVRAMなので、さらに「自分専用AI」を強化できます。
1. 日本語特化モデル「ELYZA」を試す
GoogleのGemmaも賢いですが、日本の企業が開発した elyza:8b は、より日本らしい自然な言い回しや、日本の常識に基づいた回答が得意です。
- 追加方法: 管理者パネルのダウンロード欄に
elyza:8bと入力してプル。
2. システムプロンプトで「自分専用」に染める
画像2枚目にあった 「システムプロンプト」 欄に指示を書き込むことで、AIの性格を固定できます。
- 例:「あなたは優秀なプログラミング講師です。回答は簡潔にし、必ずサンプルコードを添えてください」
- 例:「あなたは毒舌な執事です。私を叱咤激励しながらタスク管理をサポートしてください」
3. ドキュメント(PDFなど)を読み込ませる
Open WebUIのチャット欄にPDFやテキストファイルをドラッグ&ドロップしてみてください。 「この資料の内容を要約して」 と指示すれば、手元のファイルの内容に基づいた回答(RAG)ができるようになります。外部にデータが漏れないので、仕事の資料なども安心して読み込ませられます。