このpgvectorの記事を書いたのが昨年の8月ですから、月日のたつのは本当にはやいですね。
AIはテキストを文字列としてではなく、ちゃんと意味として認識しています。それは意味として多次元ベクトルの数値として保存して、かつ、その多次元ベクトルの近似値判定によって、意味が近いとか、遠いとかを判断できるようになっています。
これを利用するには、PostgreSQLをDBにして、pgvectorという拡張機能を利用したうえで、例えばOpenAI APIでベクトル数値に変換したベクトル値自体をvectorとしての型フィールドに保存しておけばSQLで判断できるようになるっていう仕組みです。
例えば、人生の経験として、似たような体験をしている人を検索するとか、言っていることは違うけど意味は近いとかってことを検索できるようになるんですよ。
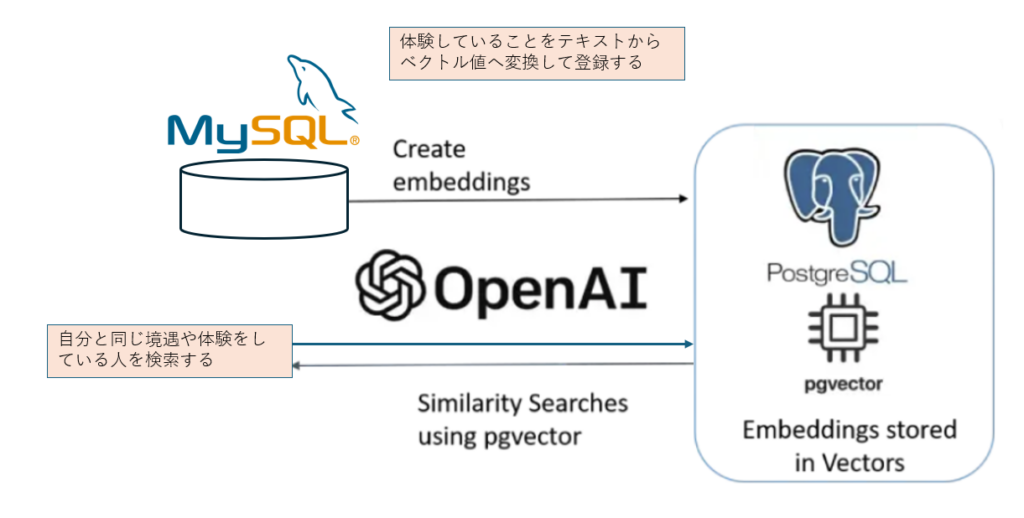
[1]あらかじめ過去の経験・体験のテキストからOpenAI APIでベクトル値を取得して、そのベクトル値をvector型のフィールドに保存しておく。
[2] あるテキストを同様にベクトル値を取得したうえで、登録してあるベクトル値との近似値検索を行う。
閾値をどうするかというところは、実際にある程度のデータを処理したうえでチューニングしていく必要があるが、近い意味を正しく検索できるようになれば第一段階クリアである。
あと目的によっては判定ロジック、閾値やDB構造が変わってきます。
- 同一エピソード判定(同じ出来事か)
- 同カテゴリ判定(似た経験のグループか)
- 学びや感情の一致(意味として近いかどうか)
こういったことをシステム内で実現したい場合には、すべて作り込む必要はなく、似たようなデータを検索したうえで、その先のロジック判定からつくればよいので、作り込む部分を大幅に削減することができます。