開発者なら誰もが一度は経験したことがあるはずです。「Kotlinで関数を書いて」と明確にプロンプトを投げたのに、LLM(大規模言語モデル)が平然とPythonを出力してくる、あるいはJavaScriptの中に他言語の構文が混ざるといった不可解な体験を。
かつてのコンピュータは、入力に対して常に予測可能な結果を返す「決定論的」な存在でした。しかし、私たちが今対峙しているのは、巨大な統計モデルが生み出す「確率論的」な世界です。なぜAIは時に開発者の意志を塗り替え、特定の言語へと「逃避」するのか。そこには、単なるミスでは片付けられない、計算機科学の歴史とAI特有の生存戦略が隠されています。
我々は今、決定論という心地よい幻想から目覚めるべき時です。最新の研究と技術的洞察が明かす、LLM時代の開発者が直面している「5つの真実」を解き明かしましょう。
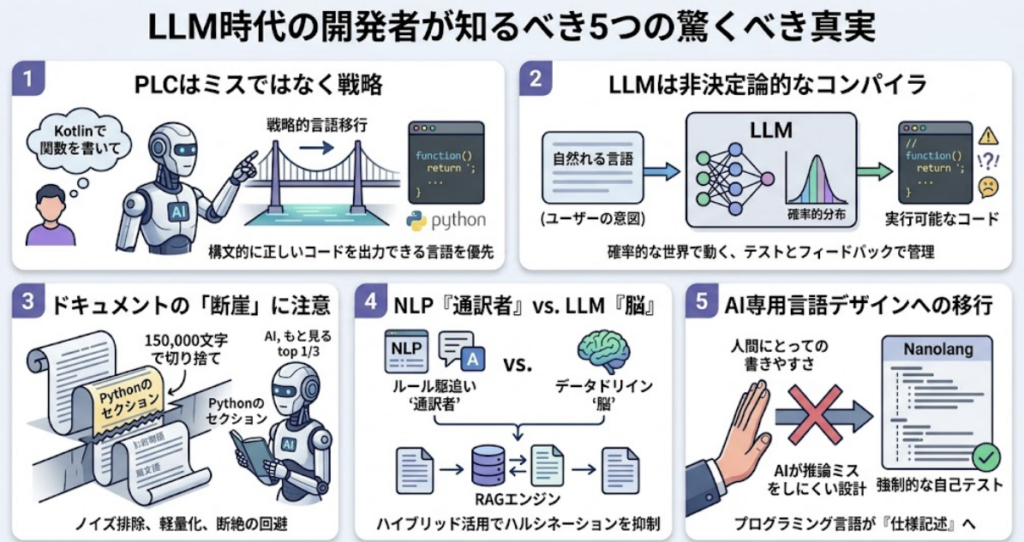
プログラミング言語の混同は、ミスではなく「戦略」である
LLMが指示と異なる言語でコードを生成する現象は、専門用語で「プログラミング言語混同(PLC: Programming Language Confusion)」と呼ばれます。最新の調査(arXiv:2503.13620v1)によれば、これは単なる学習不足ではなく、モデルによる「戦略的な言語移行」であるという側面が明らかになってきました。
特に複雑なアルゴリズムの実装を求められた際、モデルは指示された言語を維持するよりも、自分が「より構文的に正しいコードを出力できる言語」へ移動することを優先します。その強力な「アトラクター(引き寄せ役)」となっているのがPythonです。
「LLMは、明示的な指示があっても、より構文的に正しいコードを生成できる言語を優先し、一貫して『戦略的言語移行行動(strategic language migration behavior)』を示すことがわかった。モデルはPythonや、構文的に類似した言語ペアの間で強い移行パターンを示す」 — Evaluating Programming Language Confusion (arXiv)
AIがPythonで回答を返すのは、あなたの指示を忘れたからではありません。指示された言語で壊れたコードを出すよりも、得意な言語で「動くもの」を出す方が生存戦略として合理的だと判断しているからなのです。
LLMは「非決定論的なコンパイラ」という進化の系譜にある
「LLMは出力が不安定だからコンパイラとは呼べない」という反論があります。しかし、GoogleのVivek Haldar氏はこれを「的外れな指摘」と一蹴します。なぜなら、現代のコンピューティングシステム自体が、すでに非決定論的な要素の塊だからです。
ライブラリの予期せぬアップデート、ガベージコレクションの実行タイミング、JITコンパイルの挙動——これらはすべて不安定なコンポーネントですが、私たちはそれらを抽象化の層で管理し、信頼できるシステムとして運用しています。
ここで思い出すべきは、40年以上前に提唱されたシステム設計の古典的論文『End-to-end Arguments in System Design』の哲学です。「信頼できないコンポーネントを組み合わせて、信頼できるシステムを構築する」ことこそがエンジニアリングの本質であり、LLMはこの抽象化レイヤーを「自然言語という意図」にまで引き上げたに過ぎません。LLMは自然言語を実行可能なコードへと翻訳する、新しい時代のコンパイラなのです。その出力の不確実性を、テストやフィードバックループという「層」で包み込み、決定論的な体験へと昇華させること。それこそが次世代のエンジニアに求められる高度な専門技術となります。
AI向けドキュメントの「位置」より恐ろしい「断崖」
「重要な情報はページの上部と下部に置くべきだ」という、いわゆる「Lost in the Middle(中央での喪失)」対策がAI向けドキュメントの定説となっています。しかし、Dachary Carey氏の調査によれば、実務においてそれ以上に警戒すべきは、情報の位置ではなく機械的な「切り捨て(Truncation)」という断崖です。
調査では、あるエージェントが427,000文字のHTMLドキュメントを読み込もうとした際、ツール側が約150,000文字で機械的に処理を打ち切るケースが確認されました。つまり、ページの後半2/3は、AIにとって「存在すらしていない」のです。Pythonの回答が返ってきたのは、単にPythonのセクションが前方(150,000文字以内)にあったからに過ぎません。
開発者が直ちに意識すべきデータに基づく対策は以下の通りです。
- ノイズの排除: 多くのサイトでは、ナビゲーションやCSS、JavaScriptなどの「外装」がコンテキストの55〜98%を占領しています。AIが本文に到達する前に「断崖」に達しないよう、
llms.txtなどの装飾を排除したプレーンなMarkdownを提供してください。 - 物理的な軽量化: 2,000トークン(約8,000文字)程度のクイックリファレンスは、数万トークンの包括的リファレンスよりも高い精度を維持します。
- 断絶の回避: 情報が切り捨てられると、AIは不足したProcedural(手順)の詳細を古い学習データで補完し、捏造されたAPIを含む「キメラコード」を生成し始めます。
NLPは「通訳者」、LLMは「脳」である
自然言語を扱う技術としてNLP(自然言語処理)とLLMは混同されがちですが、その役割は明確に異なります。これらは対立するものではなく、ハイブリッドに活用することで真価を発揮するものです。
| 項目 | 自然言語処理 (NLP) | 大規模言語モデル (LLM) |
| 基盤 | 定義されたルールと統計構造(ルール駆動) | 膨大なデータからの学習(データ駆動) |
| 得意分野 | 情報抽出、正確な翻訳、感情分析 | コンテンツ生成、複雑な文脈理解、対話 |
| 柔軟性 | 限定的(曖昧さに弱い) | 非常に高い(パターンから推測して適応) |
NLPは「訳者」として文法を厳密に分解し、LLMは「脳」として文脈を生成します。Elastic社が提唱するように、エンタープライズ環境ではこれらを統合する「検索拡張生成(RAG)」が不可欠です。例えば「Elasticsearch Relevance Engine (ESRE)」のようなエンジンが、社内の固有データをコンテキストとしてLLMに橋渡しすることで、LLM特有のハルシネーション(APIの捏造)を抑制し、実用的な回答を生成することが可能になります。
「AI専用言語」という新たな試行錯誤
将来的にコードの99%がAIによって書かれるようになるとすれば、プログラミング言語はもはや人間にとっての書きやすさ(エルゴノミクス)を追求する必要はないかもしれません。このパラダイムシフトを見据えた実験が『Nanolang』のような「AI専用言語」です。
ここでの設計思想は、人間にとっての親しみやすさではなく、AIが推論を誤りにくいセマンティクス(意味論)に特化することにあります。
- 奇妙さの予算(Weirdness Budget): 人間の直感から多少外れていても、AIが確実にパースできる厳密な構造を優先します。
- 強制的な自己テスト: すべての関数にコンパイル時のテストを義務付け、AIが論理的誤りを生成した瞬間にエラーを吐くように設計します。
プログラミング言語は、コンパイラへの命令セットから、AIへの「仕様記述」へと変化しようとしています。人間にとっての使い勝手を犠牲にしてでも、AIの推論エラーを減らす設計——それが次世代の言語デザインの主戦場となるでしょう。
私たちは「確率」とどう向き合うべきか
AIがあなたの指示を無視してPythonを書くとき、それはAIが統計的な「確実性」を選択した結果です。LLMという非決定論的なツールを、決定論的な「正解」として扱うことには限界があります。
これからのエンジニアに求められるのは、AIが吐き出したコードの美しさに一喜一憂することではありません。出力されたものが「確率的に生成された不安定な破片」であることを理解した上で、テスト、検証、そして明確な仕様定義というエンジニアリングの基本に立ち返り、その不確実性を徹底的に管理することです。
最後に、自問してみてください。
「あなたが今日書いたコードの『言語』は、本当にあなたの意志で選ばれたものですか? それとも、AIの統計的なバイアスによって選ばされたものですか?」
私たちが向き合っているのは、もはや単純なマシンではなく、巨大な確率の海なのです。