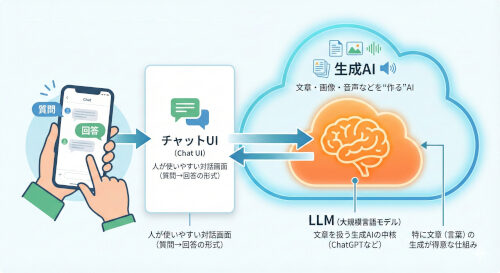
1. いま言われる「AI」は何を指しているか
最近話題のAIは、以下の3層構造で理解すると分かりやすいです。
- 生成AI:文章・画像・音声などを“作る”AIの総称
- LLM(大規模言語モデル):生成AIのうち、特に**「言葉」**を扱う中核頭脳(ChatGPTの中身など)
- チャットUI:人間が使いやすい対話画面(あくまで操作パネル)
2. LLM(大規模言語モデル)の基本イメージ
LLMを極端に単純化すると、**「次に来る言葉当てゲームの達人」**です。
仕組みの核心 大量の文章を読み込み、「この文脈なら、次に来そうな単語(トークン)は何か?」を確率で予測して並べていきます。
※ トークンとは:AIが言葉を扱う最小単位(文字のかたまり)。AIは単語そのものではなく、トークン単位で計算しています。
3. どうやって“賢く”なるのか(学習の3ステップ)
- 事前学習 (Pretraining)
- ネットや書籍の大量テキストを読み、「次の言葉」を予測し続けることで、言語のパターンや一般常識を習得します。
- 追加学習・調整 (Fine-tuning)
- 「質問に答える」「要約する」といった指示に従うよう、特定のデータで訓練し、実用的にします。
- 人の好みに合わせる調整 (RLHFなど)
- 人間が「どちらの回答が良いか」を評価し、安全性や自然さを向上させます。
4. 生成AIの「生成」の裏側
あなたが質問をした時、AIは以下の処理を高速で繰り返しています。
- あなたの入力(プロンプト)をトークンに分解
- 「次のトークンの候補と確率」を計算
- 確率に基づき1つ選ぶ(ここにランダム性がある)
- 選んだ言葉を文脈に追加し、また次を予測
Point: 毎回確率で選ぶため、同じ質問でも少し違う答えになることがあります(設定で「創造性」の度合いが変わります)。
5. チャットUIと「モデル本体」の違い
チャット画面(UI)は、あくまで「器」です。賢さの本体は裏側のモデル(LLM)にあります。
| 役割 | 具体例 |
| モデル (LLM) | 思考・生成エンジン。 実際に文章を考え、作る場所。 |
| チャットUI | 司令塔・翻訳機。 会話履歴をまとめる、検索ツールを呼び出す、結果を見やすく表示する。 |
6. 知っておくべき「限界」
LLMは万能ではありません。以下の弱点を理解しておきましょう。
- 知識は更新されない:学習時点までの情報しか持っていません(最新ニュースは検索が必要)。
- もっともらしい嘘(幻覚/ハルシネーション):確率で文章をつなぐため、事実無根でも自信満々に断言することがあります。
- 計算や厳密さが苦手:文章を作るのは得意でも、論理的な計算や手順の厳守でミスをすることがあります。
7. 生成AIの「得意・不得意」分類
実務では、この分類で使いどころを見極めます。
| 分類 | 得意度 | 向いているタスク | 注意点 |
| A. 言葉の作業 | ◎ 得意 | 要約、翻訳、メール作成、アイデア出し | 文体やニュアンスの指定が重要 |
| B. 知識の整理 | 〇 条件付 | 一般論の解説、論点整理、背景説明 | 「事実の正確さ」は要検証 |
| C. 事実確認 | △ 不得意 | 最新ニュース、統計データ、法律の現行規定 | 検索や一次情報の確認が必須 |
8. なぜ「賢い」と錯覚するのか
LLMは「文章の流れを作る能力」が非常に高いため、人間のような理解や意思があるように見えます。
実態 「意識」や「目的」を持っているわけではありません。あくまで**「人間らしい反応のパターン」**を出力しているに過ぎません。これを理解すると、過信を防げます。
9. 道具と組み合わせて真価を発揮する
最近は「LLM単体」ではなく、周辺機能とセットで使うのが主流です。
- 検索(ブラウジング):最新情報を取りに行く
- RAG(ラグ):社内文書やPDFを読み込ませて回答させる
- ツール実行:計算、グラフ作成、プログラム実行など
- エージェント:複雑なタスクを分解し、自律的に実行する
10. 安全で賢い使い方の「型」
プロンプト(指示)を出すときは、以下の要素を含めると精度が上がります。
- 目的を一言で:「何のために行うのか」
- 条件を箇条書き:「こうしてほしい」「これはNG」
- 不確かな部分は確認:「根拠も提示して」「出典を教えて」
- 最終確認:重要な事実(医療・法律・お金など)は必ず一次情報で裏取りをする
トークンとは:AIが言葉を扱う最小単位(文字のかたまり)。AIは単語そのものではなく、トークン単位で計算しています。
「トークン」は直感的にわかりにくい部分ですので、具体例で見ていくのが一番早いです。
AIにとってのトークンは、人間でいう「単語」よりも、**「意味の最小単位」や「データ処理の都合が良い区切り」**に近いです。
大きく分けて3つのパターン(英語、日本語、記号)で例を挙げます。
1. 英語の例(単語が分解される)
英語では、長い単語や変化形が分解されることがよくあります。
- 一般的な単語:
apple→ 1トークン(そのまま)
- 複合語や活用形:
smartphones→smart+phone+s(3トークンに分かれることが多い)cooking→cook+ing(2トークン)
なぜ? 「cook」とい「ing」を知っていれば、「play」+「ing」など他の単語に応用が効くため、分解して覚える方が効率的だからです。
2. 日本語の例(文字単位で刻まれる)
日本語は英語に比べて文字種(ひらがな、カタカナ、漢字)が多いため、細かく刻まれやすい傾向があります。
- よくある言葉:
こんにちは→ 1トークン(定型句なのでひとまとまり)東京都→ 1トークン(よく出る地名はひとまとまり)
- 少し複雑な文:
食べました→食べ+ました(2トークン)生成AI→生成+AI(2トークン)
- 珍しい漢字や固有名詞:
魑魅魍魎(ちみもうりょう) →魑+魅+魍+魎(4トークン、あるいはそれ以上)
ポイント 日本語の場合、だいたい 「ひらがな・漢字 1文字 〜 2文字」で1トークン くらいになることが多いです。 (※よく「日本語は英語よりトークン数を消費して料金が高くなる」と言われるのは、このためです)
3. 文字以外(スペース・数字・記号)
ここが意外な落とし穴です。文字に見えないものもトークンです。
- スペース(空白):
AI(前に空白あり) →_AI(空白込みで1トークンになることが多い)
- 記号:
。、!?→ それぞれ 1トークン
- 数字:
100→ 1トークン2025→20+25(2トークンに分かれることがある)
なぜこれが重要なのか?(計算ミスの原因)
トークンの仕組みがわかると、AIの**「計算が苦手」**な理由がわかります。
人間は 1000 + 20 を「千 たす 二十」と理解しますが、 AI(モデルによっては)これを、 10 + 00 + + + 20 のような「数字の文字列の並び」として処理してしまうことがあります。
そのため、「数字の意味」ではなく「言葉の並び」として予測してしまい、桁数が多い計算などで間違えることがあるのです。