1. はじめに:なぜAIの返答速度は「一定」ではないのか?
AI(大規模言語モデル)の運用において、推論速度は単なる「体感の心地よさ」の問題ではありません。それはインフラコストの最適化、そしてユーザー体験の質に直結する死活問題です。
「同じ質問をしているのに、なぜ2回目は返答が速いのか?」 「なぜ長いドキュメントを読み込ませると、急に応答が詰まるのか?」
こうした疑問の答えは、AIが情報を処理する際の「脳内メモリ管理」にあります。本書では、2026年現在のAI推論エンジンの二大巨頭であるvLLMとSGLang、そしてそれらが採用するPagedAttentionとRadixAttentionという革新的キャッシュ技術を徹底解説します。
まずは、AIが「計算の二度手間」を避けるために不可欠な仕組み、KVキャッシュの重要性から理解を深めていきましょう。
2. KVキャッシュの基本:AIが「計算の二度手間」を嫌う理由
AIが文章を生成する際、実は「それまでに生成・入力されたすべての単語(トークン)」を、新しい一文字を作るたびに振り返って計算しています。しかし、過去の計算結果を毎回捨ててゼロからやり直すのは、極めて非効率です。
これを料理に例えるなら、「1万ワードにおよぶ秘伝のレシピ(プロンプト)を注文されるたびに、毎回ゼロからスパイスを調合し、野菜を刻み直すシェフ」のようなものです。有能なシェフであれば、一度作った「ベーススープ(計算結果)」を冷蔵庫に保存しておき、次の工程でそれを使い回すはずです。
この「計算結果の保存場所」がKVキャッシュ(Key-Value Cache)です。しかし、この保存場所の管理には以下のボトルネックが存在します。
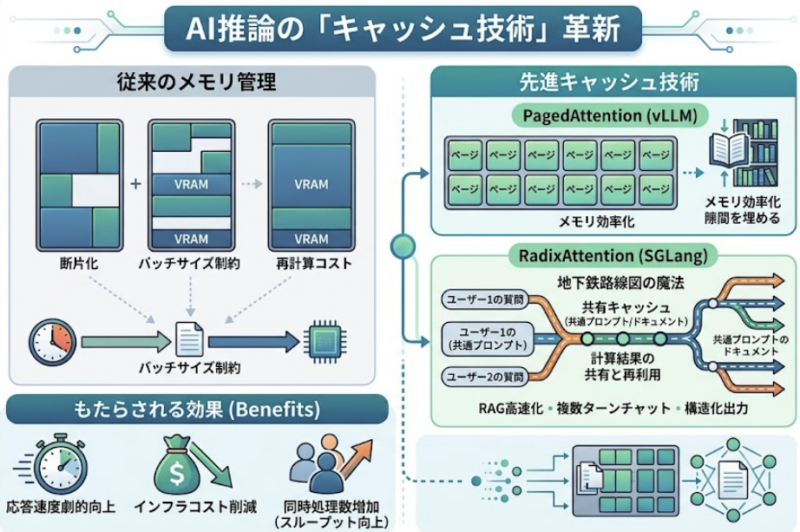
- VRAMの占有とバッチサイズの制約: メモリ管理が非効率だと「メモリの空き」が減り、同時に処理できるリクエスト数(バッチサイズ)が制限されます。メモリ効率の悪化は、そのまま処理能力(スループット)の低下に直結します。
- 断片化による「隙間」の発生: 従来の方式ではメモリを「大きな塊」で確保するため、実際には空きがあるのに新しいデータが入らない「隙間(断片化)」が生じ、リソースが浪費されます。
- 再計算のコスト: キャッシュが溢れて捨ててしまうと、再び膨大なGPU計算リソースを消費して「ベーススープ」を作り直さなければなりません。
この限られたメモリ空間を、OSの仮想メモリのようにスマートに管理する技術こそが「vLLM」の革新でした。
3. vLLMとPagedAttention:メモリの「隙間」を埋めるパズル
従来の推論エンジンは、リクエストに対して連続した大きなメモリブロックを予約していましたが、これでは利用可能なVRAMの60〜80%が「未使用の予約済み領域」として無駄になっていました。
vLLMはこの問題を解決するため、PagedAttentionを導入しました。これは、コンピュータの「OSの仮想メモリ管理」や「図書館の書庫管理」に近い概念です。
一冊の長い本(リクエスト)をそのまま棚に入れるのではなく、ページ単位(細かなブロック)に分割して、棚の空いている「隙間」にバラバラに詰め込んでいきます。物理的に離れていても、インデックスで繋がっていればAIは一つの文脈として認識できるのです。
比較:従来の管理 vs PagedAttention
| 項目 | 従来のメモリ管理 | PagedAttention (vLLM) |
| メモリの確保方法 | 連続した大きなブロックを予約 | 必要な分だけ小さなブロックで確保 |
| メモリの無駄(断片化) | 60〜80%(予約余り) | 4%未満(極限まで抑制) |
| 同時リクエスト数 | 少ない(バッチサイズが限定的) | 大幅に増加 |
| 主な付加機能 | 標準的 | Disaggregated Prefill(分散処理) |
PagedAttentionにより、メモリ浪費を劇的に抑え、スループットを飛躍的に向上させることが可能になりました。しかし、2026年の現場では「メモリの隙間を埋める」だけでは不十分です。次に、「計算結果そのものを、複数のユーザー間で共有して使い回す」SGLangの知恵を見ていきましょう。
4. SGLangとRadixAttention:二度手間を完全にゼロにする「地下鉄」の魔法
vLLMが「メモリの隙間を効率よく使う」技術なら、SGLangが採用するRadixAttentionは、「一度行った計算を、別のリクエストでも再利用する」技術です。
これを例えるなら、「枝分かれする地下鉄の路線図」です。 多くのユーザー(乗客)が、最初は「同じ主要幹線(共通のシステムプロンプトや長い文書)」を通ります。その後、それぞれの目的地(個別の質問)に合わせて枝分かれしていきます。RadixAttentionは、この「幹線部分」の計算結果を捨てずに保持し、別のユーザーが来た時に即座に再利用します。
SGLangが劇的な効果を発揮する3つのユースケース
- RAG(共有ドキュメントへの質問)
- 10人が同じ「1万語の文書」について質問した場合、SGLangは最初の1回分しか文書を処理しません。 2人目以降は計算結果を使い回すため、スループットが最大6.4倍向上することもあります。
- 複数ターンのチャット(連続会話)
- 過去の発言が「共通の接頭辞(Prefix)」としてキャッシュされます。RadixAttentionはリクエスト終了後もキャッシュを捨てない(LRUキャッシュ方式)ため、会話が続くほど、また同じ話題が繰り返されるほど速くなります。
- 構造化出力(JSON等)の高速化
- **「隠れた最強機能」として、SGLangはCompressed FSM(圧縮有限状態マシン)**を搭載しています。これにより、API等で必須となるJSON形式の出力において、標準的な手法より3倍速く、96-98%という高い形式遵守率を実現します。
メモリ管理の次は、これら2つのエンジンをどのように実務で使い分けるべきか、具体的な判断基準を提示します。
5. 【意思決定マトリクス】vLLM vs SGLang:どちらを選ぶべきか?
2026年現在の最新ベンチマーク(H100/Blackwell環境)に基づく比較表です。
| 判断基準 | vLLM (PagedAttention) | SGLang (RadixAttention) |
| 最適なワークロード | バッチ処理、ユニークな一発回答 | 連続会話、RAG、構造化出力(JSON) |
| 合計スループット | 12,500 tok/s (Llama 3.1 8B/H100) | 16,200 tok/s (Llama 3.1 8B/H100) |
| 出力トークン速度 | 413 tok/s (体感速度に影響) | 894 tok/s (2倍以上の爆速性能) |
| DeepSeek対応 | 汎用サポート | V3で3.1倍高速(FlashMLA等)、V4公認 |
| ハードウェア互換性 | 最大 (NVIDIA, Blackwell, TPU, AMD等) | 主にNVIDIA(Blackwell対応済)、AMD(DeepSeek共同) |
| サポートモデル | 広範 (T5, BART等のEncoder-Decoder対応) | Decoder-onlyが中心 |
技術的ポイントと数値データ
- コスト削減効果: H100環境で1日100万リクエストを処理する場合、SGLangへの移行だけで月間約15,000ドル(約225万円)のインフラコスト削減が期待できます。
- Blackwell(GB200)への最適化: vLLMは最新のBlackwell環境にて、毎秒26,200トークンという驚異的なプリフィル速度を達成しており、次世代ハードウェアへの即応性で一歩リードしています。
- DeepSeek V3の最適化: SGLangはFlashMLAやFlashInferなどの専用バックエンドを駆使し、DeepSeek V3においてvLLM比3.1倍という圧倒的な推論速度を実現しています。
6. まとめ:効率化がもたらすAI運用の未来
キャッシュ技術の理解は、単なるエンジニアの知識欲を満たすものではありません。それはビジネスにおいて、**「月数万ドルのGPUコストを制御し、ユーザーにストレスを感じさせないサービスを提供する」**ための最強の武器です。
2026年のAI運用において、エンジンの選択は「どちらが優れているか」ではなく「あなたのワークロードの形がどうなっているか」で決まります。
明日から取り組むべきステップ
AI運用のコストと速度を最適化するために、以下のチェックリストを実行してください。
- [ ] ワークロードの再評価: RAGや複数ターンのチャットが中心なら、SGLangへの移行でスループットが29%以上向上する可能性があります。
- [ ] プロンプトの「共通部分」を先頭に: RadixAttentionの恩恵を最大化するため、指示やドキュメントなどの共通接頭辞をプロンプトの先頭に配置する設計を徹底してください。
- [ ] ハードウェアとの整合性確認: NVIDIA環境ならSGLang、TPUやAMD、あるいはT5などの特殊なモデルを扱うならvLLMという選択が基本です。
最終メッセージ: 「仕組みを知ることは、コストを制することである」 推論エンジンの内部構造を理解し、適切なキャッシュ技術を選択することで、AIの真のポテンシャルを引き出してください。