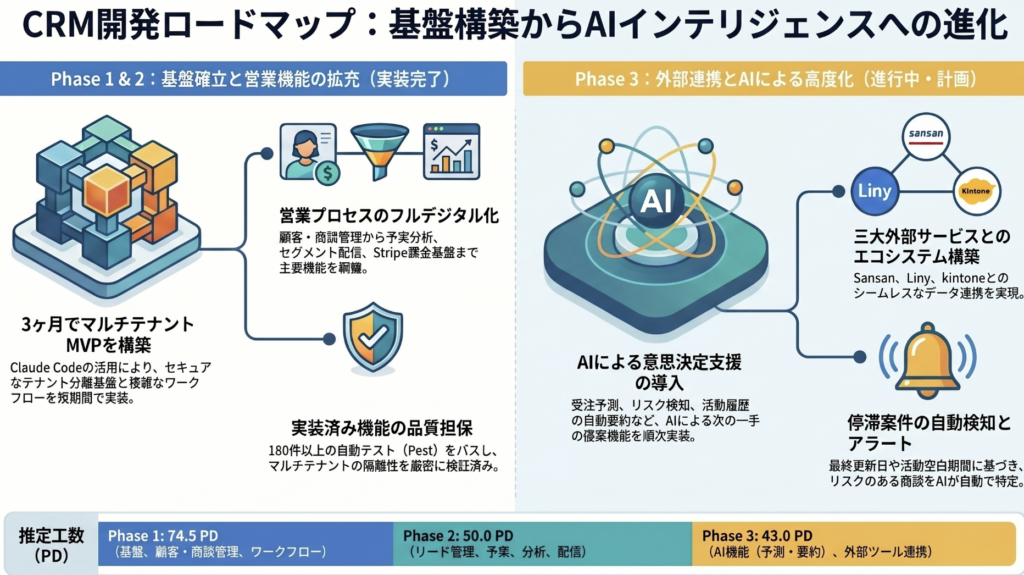
Laravel 12やMySQL 8.0などのモダンな技術スタックを用いた、マルチテナント型SaaS CRM(顧客管理システム)の機能開発についてまとめたものです。開発は全3フェーズで構成されており、ワークフローエンジンや商談管理、外部連携など、B2B営業に不可欠な機能を含んでいます。顧客基盤や予実管理、Sansan・Liny連携を含む主要機能である第一フェーズはもちろん、第三フェーズまでの計画すべての実装を完了してます。
1. 開発プロジェクトの概要と設計思想
本プロジェクトは、人間だけでやった場合には、3ヶ月という当然かかるMVP(Minimum Viable Product)構築の工数を「1人開発体制+AIの最大限の支援をうけて」で2日で完成している。そして、それはたんにシステムを生成するだけでなく、人間が不安となる将来的なAI統合とエンタープライズ利用に耐えうる堅牢性を両立させることを目的としている。(実際には、)
技術スタックと戦略的選定
本システムでは、以下のモダンかつ枯渇した技術スタックを採用している。
- バックエンド: Laravel 12(最新のPHP機能を駆使した高速開発)
- データベース: MySQL 8.0(JSON関数活用とトランザクション整合性の確保)
- フロントエンド: Vue.js 3 / Vite(リアクティブなUI開発の効率化)
- テスト基盤: Pest / PHPUnit(1人開発における回帰テストの生命線)
Claude Code活用と設計の前提条件
AIコーディングツール「Claude Code」による開発効率化(実装速度1.5倍)を最大化するため、以下の設計原則を徹底している。AIは「スパゲッティコード」において急激に精度を落とすため、**単一責任原則(SRP)**に基づいたモジュール化と、クリーンアーキテクチャの導入が必須の前提条件となる。AIがFeatureテストをスキーマ定義から自動生成できるレベルまでモデル設計を抽象化することが、高速開発の鍵である。
2. マルチテナント・データ隔離アーキテクチャ
SaaSにおいてテナント間のデータ隔離は「信頼」そのものであり、その漏洩はシステムの死を意味する重大セキュリティバグである。
「tenant_idカラム方式」の徹底実装
本システムは「シングルDB / tenant_id隔離方式」を採用し、以下の技術的ガードレールを敷いている。
- TraitによるGlobalScopeの適用: 全モデルで共通の
TenantScopedTraitを継承し、クエリ発行時に自動でWHERE tenant_id = ?を付与する。これにより、開発者がコードを記述する際、隔離を意識せずとも「越境アクセス」が物理的に不可能な構造にしている。 - 不変性の担保:
tenant_idは一度設定されたら変更不能(Immutable)とし、ミドルウェアレベルでリクエストコンテキストから自動注入する。 - 隔離テストの自動化: 180のテストパスのうち、重要な部分は他テナントのIDを指定した際に応答が404または403になることを全エンドポイントで検証する自動テストである。
戦略的メリット
開発序盤でこの基盤を確立したことで、将来的に開発人数が増加したり、AIがコードを生成したりする際にも、基盤側でデータ隔離を強制できる。これは長期的な運用保守コストとセキュリティリスクを劇的に低減させる戦略的投資である。
3. GUIベース・ワークフローエンジンの構造と制御論理
本システムの競争優位性の源泉は、業務プロセスをノンプログラミングでデジタル化するワークフローエンジンにある。
ロジック評価エンジンの分離
本エンジンは、UI(Vue.js)とロジック(Laravel)を完全に切り離した「ロジック評価エンジン」として構築されている。
- データ構造:
workflow_definition(マスタ)、step_definition(承認工程)、condition_rule(分岐条件)、action_log(証跡)の4層で構成。 - ルールビルダー: 金額、部署、役職、商材などの動的なパラメータに対し、GUI上で演算子(以上、以下、含む等)を組み合わせた条件分岐が可能。
- 高度な制御: 期間指定可能な「代理承認」や、役職マスタと連動した「承認者自動決定ロジック」を実装。
開発リスク管理
ワークフロー機能は全体工数の約27%を占める「最大リスク領域」であった。この複雑性に対処するため、内部的にはステートマシンの概念を採用し、GUIの変更がビジネスロジックの破壊を招かない設計としている。これにより、コンプライアンス上重要な「操作ログ(監査証跡)」の整合性を常に保ちつつ、UI側の柔軟な拡張を可能にしている。
4. 外部システム連携基盤とAI拡張ロードマップ
SaaSとしての市場価値は、外部エコシステムとの接続性によって決定される。現在、Phase 3の前半にあたる「連携モジュール」の実装は全て完了している。
実装済み外部連携(Phase 3 完了分)
- Sansan連携: Webhookによる名刺情報の自動取り込みと顧客マスタへのマージ。
- Liny連携: LINE接点のリード情報の双方向同期。
- kintone連携: 商談情報のリンクに加え、国税庁APIを利用したインボイス番号の照会・照合機能を実装し、エンタープライズ級のバックオフィス要件に対応。
AI拡張ロードマップ(次フェーズ)
外部連携で集約された「質の高いデータ」を元に、以下のAI推論レイヤーを統合する。
- 受注予測・リスク検知: 停滞日数やBANT情報の欠落をトリガーとしたAIスコアリング。
- AI音声文字起こし・要約: Whisper API等を利用した活動履歴の自動生成。
- アクション提案: AI予測スコアを根拠とした「次にとるべき行動」のレコメンド。
5. 1人開発体制における品質保証とCI/CDパイプライン
開発者が1名である制約下で品質を維持するため、手動テストを徹底的に排除した自動化戦略を構築している。
自動化の構成
- Pestによるテスト駆動: 単体テストだけでなく、マルチテナントの隔離テスト、ワークフローの全承認パターン(差し戻し、代理等)を含む180のテストパスを構築。
- CI/CD: GitHub Actionsにより、全プッシュで自動テストと静的解析を実行。
- AI共創QA: Claude Codeに対し、モデル定義からFeatureテストを生成させ、人間が「仕様の正しさ」だけを確認する体制を構築。
戦略的評価
「180のテストパス」は単なるバグ防止策ではない。1人開発において最大のボトルネックは「修正による他機能への影響確認(回帰テスト)」である。これを自動化したことで、3ヶ月という納期内での高速開発と、大規模組織の利用に耐えうる品質を両立させた。
6. 実装ステータスと今後の発展
現在の到達点
現在、Phase 1(基盤・ワークフロー)、Phase 2(リード・分析・課金)、およびPhase 3(外部連携:Sansan/Liny/kintone)までの全機能(GitHub Issue #1-52)が100%完了している。現在のコードベースは、非常に高いテストカバー率と疎結合な設計を維持している。
AI機能実装に向けた意思決定マトリクス
最終フェーズとなるAI機能の実装に向け、以下の設計論点を整理している。
| 設計論点 | 採用方針 | 理由 |
| AI結果の保存先 | ai_inference_logs + 各モデルのメタデータ | 監査証跡の保持と、UIでの高速表示を両立するため |
| 受注予測の計算 | 商談更新時の非同期処理(Queue) | リアルタイム性とサーバー負荷のバランスを最適化 |
| リスク検知ルール | 重み付け設定可能なルールエンジン + AI | 判定根拠を透明化し、ユーザーの納得感を高めるため |
| AI文字起こし | Whisper API + Claude 要約 | 高精度な構造化データ抽出を実現するため |
最終評価
本システムは、初期設計においてマルチテナント基盤とワークフローエンジンの「核」を堅牢に構築したことで、Phase 2の「予実分析」やPhase 3の「外部連携」を極めてスムーズに統合することに成功した。現在のアーキテクチャは、今後追加されるAI推論レイヤーを容易に受け入れる十分な柔軟性と、エンタープライズ用途に応える保守性を備えている。本定義書を、最終フェーズの完遂およびその後の安定運用の指針とする。