1. 導入の背景と本評価の目的
企業のデジタル戦略において、AIはもはや単なる「効率化ツール」ではなく、自律的に判断し実行を支援する「高度な共同作業者(Collaborator)」へと進化を遂げています。Anthropic社が発表した最新モデル「Claude Opus 4.8」は、前モデル4.7の課題を解消し、エージェント能力を大幅に強化した戦略的アップデートです。
本評価書では、プログラミング、法務、金融といった、極めて高い専門性と正確性が求められるドメインにおける「意思決定の質」への影響を分析します。Opus 4.8は、単なる性能向上に留まらず、数週間後に控えるMythosクラスの次世代モデル(Project Glasswing)への即時的なブリッジとして機能します。企業がAIに対して抱いてきた「出力の不確実性」を解消し、人間の役割を「Human-in-the-loop(作業への介在)」から「Human-on-the-loop(高次元の監視)」へとシフトさせる、その戦略的重要性について詳述します。
--------------------------------------------------------------------------------
2. 業務制御の革新:エフォート制御とダイナミックワークフロー
従来のAI利用における最大の障壁は出力品質の不確実性でしたが、Opus 4.8は「エフォート制御(Effort Control)」と「ダイナミックワークフロー(Dynamic Workflows)」により、企業に実行の制御権を返還しました。
エフォート制御によるリソース最適化
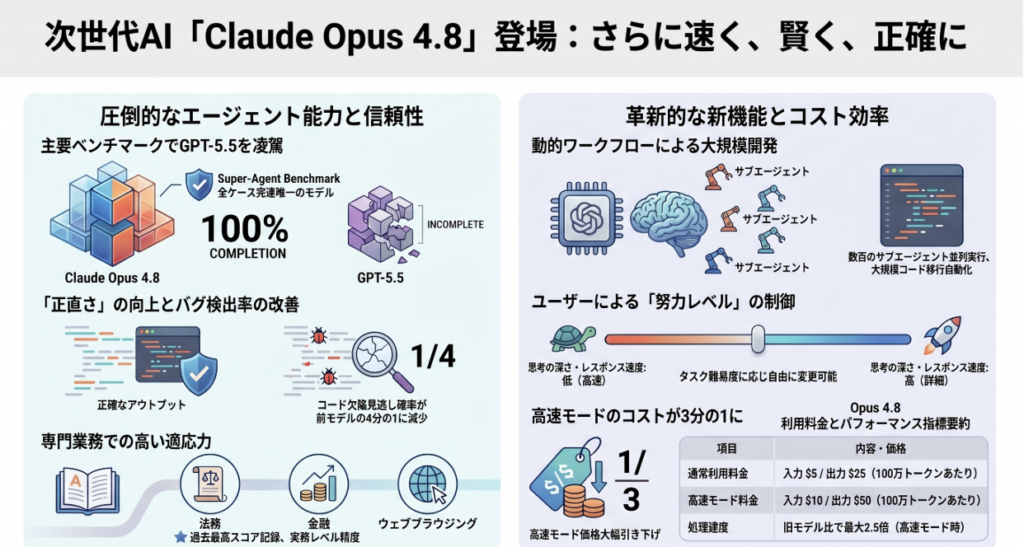
ユーザーはタスクの重要度に応じて思考の深さを選択可能です。
- High(デフォルト): 品質とレスポンス速度の最適バランス。
- Extra(Claude Code内では"xhigh"と指定)/ Max: 高難易度タスクや非同期ワークフローにおいて、より多くの思考トークンを投入。 これにより、定型業務でのレートリミット節約と、重要局面での最大限の知能投入を両立させ、ROIを最大化します。
ダイナミックワークフローとMessages APIの刷新
Research Previewとして提供される「ダイナミックワークフロー」は、数百のサブエージェントを並列実行し、自己検証を経て成果物を出す機能です(Enterprise, Team, Maxプランで利用可能)。 さらに、Messages APIのアップデートにより、タスク実行の途中でプロンプトキャッシュを壊すことなく、システム指示(権限設定や予算制限など)を動的に更新可能となりました。これは、エージェントの柔軟性を高めつつ、計算コストを劇的に抑制する技術的ブレイクスルーです。
ビジネスへのインパクト:自律的な業務遂行(Unattended Workloads)
これらの機能は、AIが不健全な計画に対して「異議を唱える(Push back)」能力と相まって、監視コストを劇的に削減します。数十万行のコードベース移行といった大規模課題において、人間が細部を監視せずとも「検証済み成果物」を受け取れる体制への道筋を提示しています。
--------------------------------------------------------------------------------
3. 専門ドメイン別:精度と信頼性の詳細分析
Opus 4.8は、競合モデルであるGPT-5.5と比較しても、実務における「プロフェッショナル基準の品質(Fiduciary-grade)」において優位性を示しています。
プログラミング:品質保証とノイズの低減
エンジニアリング領域では、Opus 4.7で見られた「コメントの冗長性(comment-verbosity)」や「ツール呼び出し(tool-calling)」のエラーが修正されました。特筆すべきは、「コード内の欠陥を、見逃さずに指摘する確率(Proactive flagging)」が前モデルの4倍に向上した点です。DevinやCursor等のツール利用が効率化され、自律的なエンジニアリング・ワークロードの安定性が増しています。
法務分析:実務を自信を持って委ねられる精度
Legal Agent Benchmarkにおいて、全タスク合格基準(all-pass standard)で初めて10%を突破し、過去最高スコアを記録しました。Super-Agentベンチマークでは、コストを同等とした条件下でGPT-5.5を上回り、唯一全ケースをエンドツーエンドで完遂しました。CoCounsel等を利用する法務・税務のプロフェッショナルが、AIの成果物を「信頼して実務に適用できる」水準に達しています。
金融・データ分析:情報密度の高い文書への対応
HebbiaやDatabricks(Genie)での検証により、引用の正確性(Citation Precision)の向上が確認されました。マルチモーダル推論が強化され、複雑なPDFや図表を含む非構造化データを直接解析可能となり、かつそのトークンコストを従来比で61%削減しています。
--------------------------------------------------------------------------------
4. 企業ガバナンスに対応する「誠実性」と「アライメント」
企業導入における最大のリスクである「ハルシネーション」に対し、Opus 4.8は「誠実性(Honesty)」という軸で明確な改善を示しています。
不確実性の自己申告によるリスク管理
Opus 4.8は根拠のない主張を避け、作業の不確実性を積極的にフラグ立てする特性を持ちます。エンジニアリング分野でコードの欠陥を「無言でスルー」しない確率は前述の通り4倍に向上しており、この「知ったかぶり」の抑制が、人間側のレビュー負荷を劇的に軽減します。
最高水準の安全性とアライメント
Anthropicのアライメント評価では、ユーザーの自律性を尊重する「親社会的な特性(Prosocial traits)」で新記録を樹立。欺瞞的挙動や悪用への加担率はOpus 4.7より大幅に低下し、最高位の安全性を持つ「Claude Mythos Preview」と同等の評価を得ています。この高い誠実性は、企業のコンプライアンス基準を満たした自動化を推進する上で不可欠な要素です。
--------------------------------------------------------------------------------
5. 経済性および生産性の統合評価
Opus 4.8は、コスト構造においてもエンタープライズ向けの最適化が行われています。
コストパフォーマンスと価格体系
実行速度を2.5倍に高めた「Fast mode」は、前モデル比で3倍の低価格化を実現しました。
- 通常モード: 入力 $5 / 出力 $25(100万トークンあたり)
- Fast mode: 入力 $10 / 出力 $50(100万トークンあたり)
導入メリットと戦略的データ
| 導入メリット | 主要指標・データポイント | 想定される具体的な活用シーン |
| 信頼性の飛躍的向上 | コード欠陥の見逃しが4倍減少 / GPT-5.5をベンチマークで凌駕 | 大規模移行、高度なセキュリティ監査 |
| 業務の自律化(Agentic) | Super-Agentベンチマーク全完遂 (唯一のモデル) | 複雑なリサーチ、スライド自動作成、法務精査 |
| コストの劇的改善 | マルチモーダル推論コスト 61% 削減 | 膨大な財務諸表(PDF・図表)の自動分析 |
| 開発効率の最適化 | Messages APIによるミッドタスク指示更新 | 動的なエージェント制御、インフラ運用自動化 |
総括
Claude Opus 4.8は、単なる性能向上版ではなく、企業の「高度な知的業務の信頼できるパートナー」としての地位を確立しました。不確実性を自己申告する誠実さと、GPT-5.5を凌駕する実務遂行力は、AIへの過度な依存リスクを低減しつつ、自動化の恩恵を最大化します。
数週間後に控えるProject Glasswing(Mythosクラス)の一般公開を見据え、現時点からOpus 4.8をベースとした統合テストを開始することは、次世代のAI競争力を確保する上で極めて妥当な投資であると判断します。