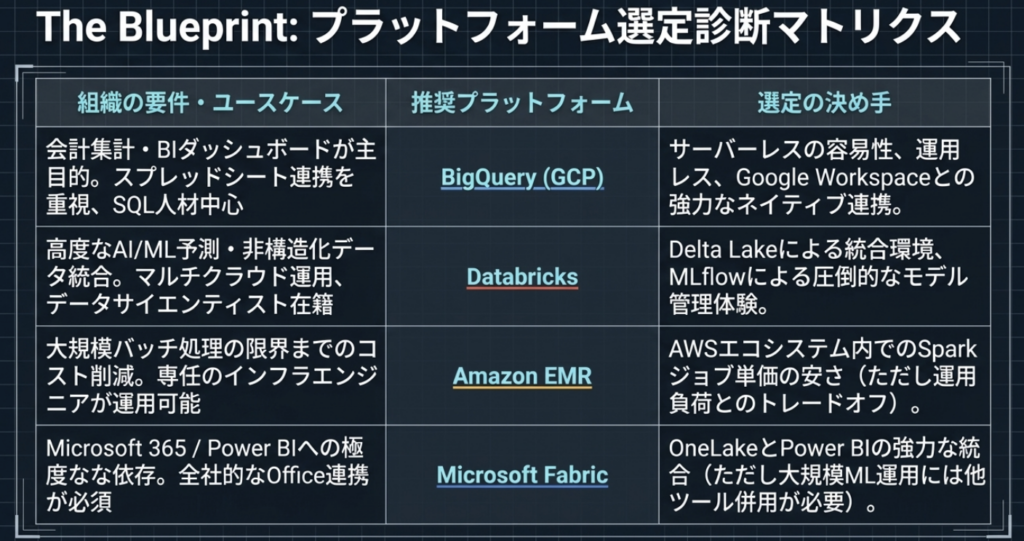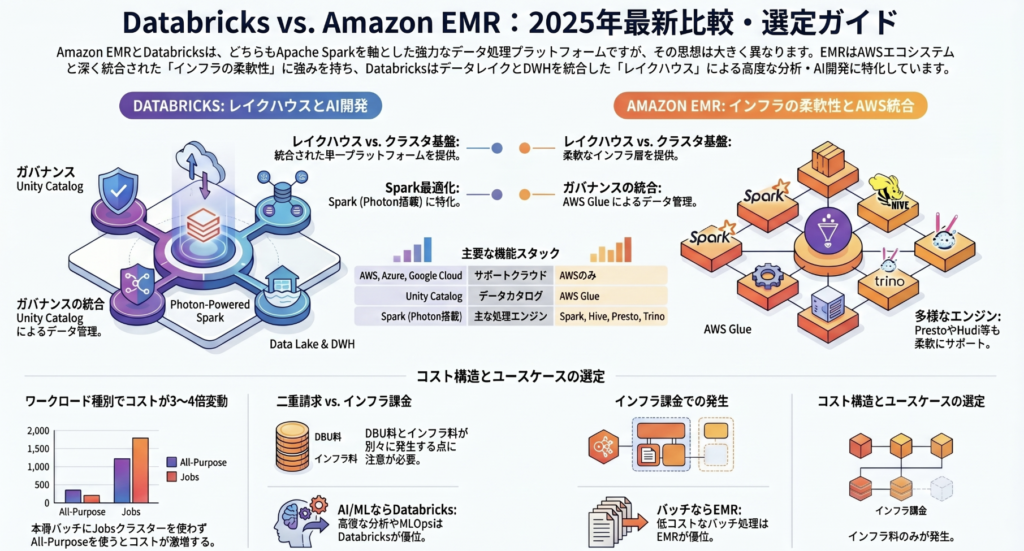
1. イントロダクション:データの「分断」という戦略的負債
現代のエンタープライズにおいて、データは最大の資産であると同時に、管理の複雑さがもたらす「戦略的負債」にもなり得ます。多くの組織が、分析用のデータウェアハウス(DWH)と機械学習用のデータレイクという、技術的・組織的に分断された「2層アーキテクチャ」に苦しんでいます。この構造的な欠陥は、データの冗長性とSSOT(Single Source of Truth:信頼できる唯一の情報源)の喪失を招き、意思決定のスピードを致命的に鈍化させています。
こうした状況下で、なぜAWSやGoogle Cloudといった巨大プロバイダーのネイティブサービスを差し置き、多くの先進企業があえて独立系のDatabricksを基盤の核に据えるのでしょうか。本稿では、数多くのデータ基盤移行を手掛けてきたシニア・アーキテクトの視点から、単なるツール比較を超えた、次世代データ基盤の「真の勝機」を解き明かします。
--------------------------------------------------------------------------------
2. Takeaway 1:データアーキテクチャの終着点「レイクハウス」の衝撃
従来の「2層アーキテクチャ」は、データの移動に伴うETLパイプラインの肥大化と、それに起因するデータの「陳腐化(Staleness)」という問題を抱えていました。分析者が目にするデータが数時間、あるいは数日前のものという状況では、リアルタイムな経営判断は不可能です。
Databricksが提唱する「データレイクハウス」は、この課題に対する根源的な解です。これを技術的に成立させているのが、オープン形式(Parquet)の上に配置される「メタデータレイヤー」としてのDelta Lakeです。
- メタデータレイヤーの役割: オブジェクトストレージ上にACIDトランザクションとスキーマ適用、タイムトラベル(履歴管理)を実装し、DWHレベルの信頼性を安価なレイク上で実現します。
- SSOTの確立: データの複製を繰り返すことなく、単一のデータソースに対してBI分析と機械学習の双方が直接アクセス可能になります。
「データレイクハウスとは、データレイクの柔軟性とデータウェアハウスの管理機能を取り入れたオープンで新たなアーキテクチャである」
このアーキテクチャへの転換は、もはやエンジニアリングの効率化に留まらず、組織全体のデータリテラシーを底上げするための「戦略的 imperatives(不可欠な要素)」なのです。
--------------------------------------------------------------------------------
3. Takeaway 2:クラスター選択ミスでコストが「4倍」跳ね上がるという真実
シニア・アーキテクトとして、私が最も厳しくチェックするのが「計算リソース(クラスター)のROI」です。Databricksの料金体系は非常に合理的ですが、その「使い分け」を誤るとコスト効率は劇的に悪化します。
特に「Jobs Compute」と「All-Purpose Compute」の単価差は決定的です。
【クラスター種別によるコスト・役割の対比】
| コンピュート種別 | Premium単価(AWS目安) | 戦略的用途 | 備考 |
| Jobs Compute | 約 $0.15 / DBU | スケジュールETL、バッチ | ROIのチャンピオン |
| All-Purpose Compute | 約 $0.55 / DBU | 対話型開発、探索的分析 | アイドリングリスクを含む単価設定 |
アーキテクトとしての警告:
- スポットインスタンスの活用: フォールトトレラントなバッチ処理にスポットインスタンスを採用することで、VMコストを60〜80%削減可能です。これはJobsクラスター運用の定石です。
- Photonエンジンの真価: PhotonランタイムはDBU単価にプレミアムが乗りますが、実行速度が劇的に向上するため、結果として総DBU消費量が減り、TCO(総所有コスト)を抑制できるケースが多々あります。
本番ジョブをJobsクラスターへ正しく再分類し、Photonとスポットインスタンスを適切に組み合わせる。これだけで、基盤の経済性は一変します。
--------------------------------------------------------------------------------
4. Takeaway 3:意外と知られていない「請求書が2通届く」二重構造の罠
Databricksの予算策定において、多くの担当者が陥る落とし穴が「二重請求構造」の理解不足です。利用者は、以下の2系統から個別に請求を受けます。
- Databricksからの請求: ソフトウェア利用料(DBU)。
- クラウドプロバイダーからの請求: インフラ利用料(VM、ストレージ、ネットワーク等)。
ここでの驚くべき事実は、「インフラコストがソフトウェアコストを上回るケース」が頻出することです。
【Small SQL Compute クラスターの試算例(Azure)】
- DBU費用: 約 $2.64 / 時
- VM/インフラ費用: 約 $3.89 / 時
- 合計実コスト: 約 $6.53 / 時
このように、DBU単価だけを見て予算を組むと、総支出を50%〜200%も過小評価するリスクがあります。インフラ側を含めたスタック全体の透明性を確保し、ガバナンスを効かせることが、シニア・マネジメント層に求められる規律です。
--------------------------------------------------------------------------------
5. Takeaway 4:AI/RAG開発の「最短ルート」としての立ち位置
昨今の生成AI(LLM)活用において、Databricksは単なる集計基盤を超え、RAG(検索拡張生成)の強力なバックエンドとして君臨しています。
最大の優位性は、**「非構造化データと構造化データの一元処理」**にあります。
- 統合パイプライン: 例えば「領収書画像(OCR)」や「契約書PDF」といった非構造化データを、基幹システムの構造化データと同じパイプラインで加工・ベクトル化できます。
- MLflowによる管理: 開発したモデルやプロンプトのバージョン管理、デプロイまでをMLflowで完結させ、ガバナンスの効いたMLOpsを即座に構築可能です。
Amazon EMR等のネイティブサービスでは、別途SageMakerやOCRサービスを繋ぎ合わせる複雑な「スパゲッティ構成」になりがちですが、Databricksはこれを単一プラットフォームで圧縮します。この「複雑性の排除」こそが、AI時代における開発スピードの源泉です。
--------------------------------------------------------------------------------
6. Takeaway 5:マルチクラウドという「戦略的自由」と監査ガバナンス
特定クラウドベンダーへのロックインは、将来的なインフラ戦略の硬直化を招きます。AWS EMRやGoogle BigQueryは強力ですが、そのエコシステムから抜け出すコストは甚大です。
Databricksは、主要クラウド(AWS/Azure/GCP/Alibaba)を横断して動作する汎用性を持ち、それを支えるUnity Catalogが「クラウドを跨いだ一元的なデータガバナンス」を提供します。
- ボードレベルの価値(監査とコンプライアンス): Unity Catalogが提供する「データリネージ(データの系譜)」は、単なる技術マップではありません。財務監査や規制対応において、「どのソースから、誰が、どのような加工を経てこの数字を算出したか」を即座に証明するための、経営層向けの信頼担保ツールです。
- ビジネスユーザーへの開放: AWS Glueのような「エンジニア向けの技術カタログ」とは異なり、ビジネスユーザーが直接データを探索・活用できるインターフェースを提供し、データの民主化を加速させます。
--------------------------------------------------------------------------------
7. 結論:未来のデータ戦略への問いかけ
Databricksは、もはや単なる「速いSpark」ではありません。エンジニアリングの複雑性を圧縮し、AI時代のビジネス価値を最大化するための「統合オペレーティングシステム」です。
表面的なDBU単価に惑わされてはいけません。運用負荷の軽減、開発スピードの向上、そしてベンダーロックインからの解放。これらを総合した「投資対効果」で判断したとき、Databricksがモダンデータスタックの覇者である理由は自明となります。
最後に、あなたに問いかけます。 「あなたの組織のデータ基盤は、5年後のAI時代に耐えられる『レイクハウス』へと進化する準備ができていますか?」