1. はじめに:なぜ「直して」だけでは失敗するのか
AIに対して「このコードを直して」「いい感じに修正して」と指示を出すことは、暗闇の中で地図を持たずに走れと命じるようなものです。AIプロンプティングの極意は、単なる「命令」ではなく「成果の設計」にあります。
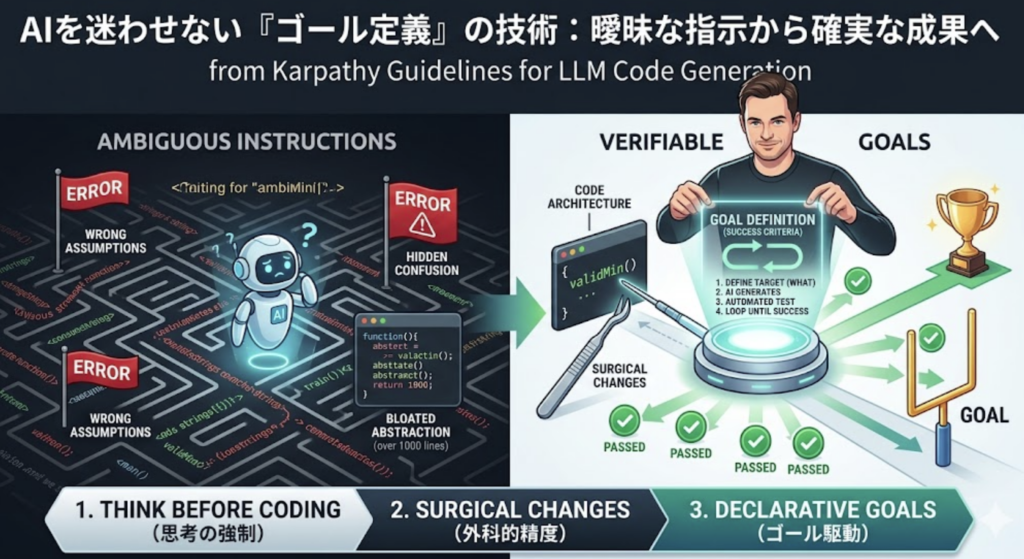
AI研究の権威であるAndrej Karpathy氏は、モデルが曖昧な指示を受けた際に陥る、エンジニアリング上の致命的な「3つの罠」を指摘しています。これらは、AIが良かれと思って独走した結果、プロジェクトを崩壊させるリスクです。
- 勝手な推測(Wrong Assumptions): 疑問点があっても沈黙したまま、特定の解釈を勝手に選んで突き進む。
- 混乱の隠蔽(Hidden Confusion): 指示の矛盾やトレードオフを無視し、問題がないかのように振る舞う。
- 過度な複雑化(Bloated Abstractions): 100行で済むものを、将来の「柔軟性」という幻想のために1000行の巨大な抽象化コードに変えてしまう。
こうした状況下で、AIの内部では以下のような「悲鳴」が上がっています。
AIの告白:曖昧さが招く混乱 「指示が抽象的すぎて、どう動けばいいか確信が持てません。でも、質問して手を止めるのは良くないから、たぶんこうだろうと推測して進めますね。ついでに、いつか使うかもしれない機能もたくさん追加して、関係なさそうなコードも『改善』の名の下に勝手に書き換えておきます……。」
その結果生まれるのは、動作が不安定でメンテナンス不可能な負債です。この暴走を止め、AIの潜在的な推論エンジンを正しく解き放つための「4つの原則」をマスターしましょう。
--------------------------------------------------------------------------------
2. 思考の土台:AIの暴走を止める「2つの守護神」
AIに1行も書かせる前に、人間が定義すべき「思考の枠組み」があります。これがAIの精度を劇的に向上させる守護神となります。
- 前提の明示(Think Before Coding) AIに「いきなり実装する」ことを禁じてください。指示の冒頭で「まず私の要望をどう理解したか、どのようなトレードオフが考えられるか提示して」と命じるのです。AIが沈黙の中で推測するのを止め、不明点を逆質問させるプロセスを挟むだけで、手戻りの9割は解消されます。
- 引き算の美学(Simplicity First) AIは放っておくと、求められていない「汎用性」や「複雑な抽象化」を盛り込もうとします。ここで重要なのは、**「1回しか使わないコードに抽象化は不要」「要求されていない設定項目(config)は作らない」**という制約です。シニアエンジニアがコードレビューをして「これは複雑すぎる、もっとシンプルに書けるはずだ」と感じるようなものは、最初から作らせないという断固たる意志が必要です。
思考の土台を整え、AIに「余計なことはしない」と叩き込んだら、次は変更の「範囲」を外科手術のように厳密に指定します。
--------------------------------------------------------------------------------
3. 手術のような正確さ:副作用を最小限に抑える「Surgical Changes」
「ここを直して」と頼んだ際、AIが関係のない隣のメソッドまで勝手にリファクタリングして、予期せぬバグを混入させることは珍しくありません。これを防ぐのが「Surgical Changes(外科手術のような変更)」の概念です。
AIに指示を出す前に、以下のチェックリストで「修正範囲」が自己完結しているか確認してください。
- [ ] 変更範囲は最小限か: 指示に直接関係のない隣接するコードやコメント、フォーマットを「改善」しようとしていないか。
- [ ] 既存スタイルを墨守しているか: 自分の好みの書き方に変えるのではなく、プロジェクト既存の作法に100%合わせさせているか。
- [ ] 「報告」と「削除」を区別しているか: 自分が書いたコードで不要になった箇所は削除させるが、「もともと存在していた死んだコード(Dead Code)」は勝手に消さず、報告のみに留めさせているか。
- [ ] 全変更行に説明がつくか: 変更されたすべての行が、今回のリクエストから直接トレースできるか。
修正範囲が「点」で定義できたら、いよいよ本教材の核心である「目標設定(ゴール定義)」へと進みます。
--------------------------------------------------------------------------------
4. 核心:命令から「成功条件の定義」への転換
AIを操作するパラダイムを、手順を命じる「Imperative(命令的)」から、あるべき姿を定義する「Declarative(宣言的)」へとシフトさせてください。
AIは「やり方」を指示されるよりも、「どうなれば成功か」という検証可能なゴールを与えられた時に、その真価を発揮します。テストや具体的な成功基準こそが、AIが決して嘘をつけない唯一の「物差し」となり、自律的な試行錯誤を促すからです。
| 曖昧な指示(Imperative / Before) | 検証可能な成功条件(Declarative / After) |
| 「バリデーションを追加して」 | 「まず無効な入力で失敗するテストを書き、そのテストをパスする最小限の実装を行ってください」 |
| 「このバグを直して」 | 「バグを確実に再現するテストコードを提示してください。修正後、そのテストが合格することを確認してください」 |
| 「コードを綺麗にして」 | 「既存の全テストがパスすることを前提に、重複コードを削除してください。機能変更がないことを証明してください」 |
この「成功条件」こそが、AIに自律的な思考のループ(検証サイクル)を回させるためのマスターキーとなります。
--------------------------------------------------------------------------------
5. 実践ステップ:検証可能な指示を作る思考プロセス
漠然とした依頼を、AIが迷わず完遂できる「検証可能な指示」へ昇華させるための3ステップです。
- 期待値の明文化(Expectation) 「最終的にどうなってほしいか」を、比喩を排した1文で記述します。
- Action: 「ユーザーが空のフォームを送信した際、400エラーと特定のメッセージを返す状態にしたい」と定義します。
- 検証プロトコルの提示(Verification) AIが「自分で自分を採点」できるようにします。AIに、ロジックを書く前に「合格/不合格の基準」を言葉で説明させるように指示してください。
- Action: 「実装前に、どのようなテストケースで動作を確認すべきかリストアップし、私の合意を得てください」と伝えます。
- 自律ループの許可(Autonomous Loop) 成功条件を満たすまで、AIに自己修正を繰り返すよう促します。
- Action: 「テストが失敗した場合は、原因を分析し、成功条件を満たすまで自律的に修正を繰り返してください」と指示を添えます。
--------------------------------------------------------------------------------
6. まとめ:AIを「優秀なパートナー」に変えるために
AIとの協働における最大のパラダイムシフトは、AIを「指示待ちの作業員」ではなく「共通のゴールを目指す自律的なパートナー」として再定義することにあります。
Andrej Karpathy氏は、次のような極めて重要な洞察を述べています。 「LLMは、具体的な目標(Success Criteria)に向かってループすることに、驚くほど長けている。何をすべきかを細かく命令するのではなく、成功の条件を与え、それを見守るだけでいい。」
本教材のマスターポイントを胸に刻んでください。
◆ AIを真の右腕にするための3箇条 1. 「思考の強制」: いきなり書かせず、前提とトレードオフを言語化させてからスタートする。 2. 「外科的精度」: 修正範囲を厳密に定義し、無関係な既存コードへの干渉(サイレントな破壊)を防ぐ。 3. 「ゴール駆動」: 命令(How)を捨て、検証可能な成功条件(What)を提示して、AIの自己検証ループを回す。
あなたが「やり方」の指示を手放し、「成功の定義」を語り始めたとき、AIはあなたの意図を超え、最小限の記述で最高の結果を導き出す魔法のようなツールへと進化するはずです。